Estimated playback time: 12min
The major general-purpose Visual Language Models (VLMs) - GPT-4o, Gemini 1.5 Pro... - already know how to combine text and image. However, in regulated B2B contexts (financial, legal, insurance, etc.), they pose three problems:
- High cost of inference: large-scale deployment on massive document flows quickly weighs on OPEX.
- Confidentiality: it's impossible to systematically send sensitive documents to a third-party cloud.
- Business specificity: a Korean invoice or an agricultural lease imposes a granularity that generalist models have not learned.
Mid-sized VLMs (2 - 15 B parameters) offer a compromise: fine-tunable, portable on a 16 GB GPU and capable of matching (or even surpassing) the larger models on highly targeted tasks.
This article shows how to adapt an open-source model (Qwen-VL-7B-Instruct) to a concrete task: extracting structured information from receipts (dataset CORD-V2).
All this in less than an hour on Google Colab, without any heavy infrastructure, and with performance close to that of GPT-4o.
Summary
- Why Small VLMs? Medium-sized Visual Language Models (2B-15B) enable fine-tuning to specific business cases, while remaining compatible with a 16 GB GPU, offering a good compromise between performance, cost and portability.
- Fast, accessible fine-tuning Using the Unsloth framework and a quantized model (Qwen-VL-7B in 4-bit), fine-tuning with QLoRA can be done in less than an hour on Google Colab.
- Competitive results The fine-tuned model achieves results very close to those of GPT-4o.
- Demonstrated use case The structured extraction of receipts from images (dataset CORD-V2) demonstrates that these VLMs are suitable for complex multimodal tasks.
Setup: model, infrastructure, dataset
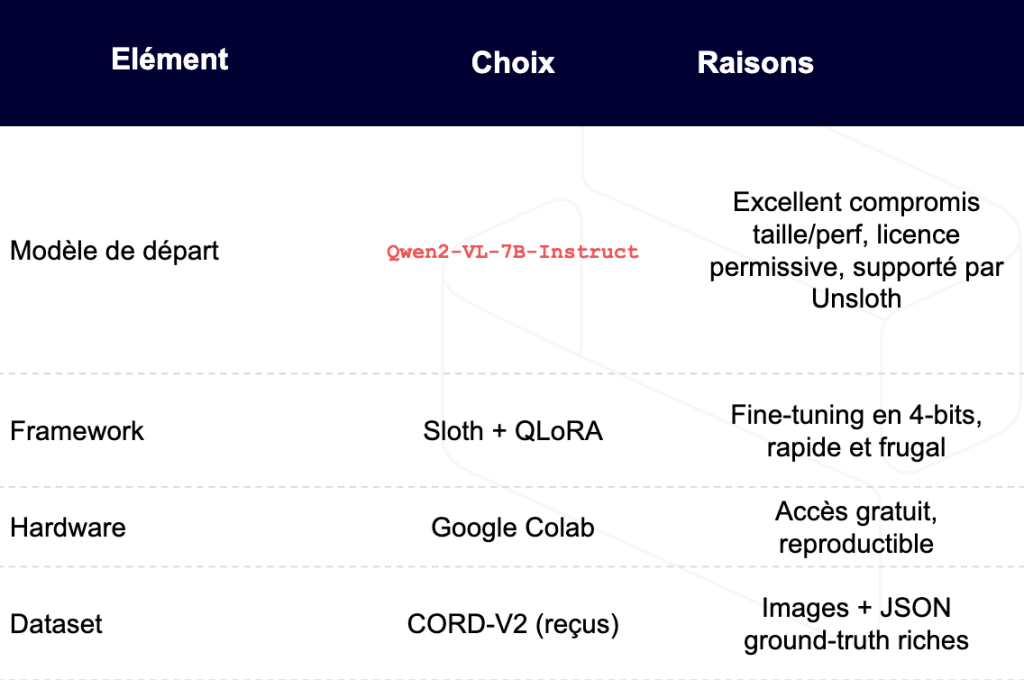
Here's an example of how easy it is to fine-tune this kind of model at low cost, without the need for expensive hardware or endless training.
For our example, we chose the Qwen2-VL-7B-Instruct model, a high-performance Chinese open source model. For maximum efficiency, we opted for Unsloth, a lightweight library for rapid training of 4-bit quantized models, including our Qwen-VL-7B model, which we will fine-tune into QLoRA (LoRA on a Quantized model).
You'll notice that this configuration fits nicely on a 16GB RAM GPU, which is available for free on Google Colab!
Let's get to the heart of the matter: the code.
Fine-tuning in practice
We started from this notebook shared by Unsloth: Unsloth Notebook fine tuning llama Vision
And here's our Colab notebook: VLM Finetuning notebook
Note on Unsloth: the framework is still under active development. Depending on the models used, you may encounter some instabilities (e.g. undetected image or inconsistent response).
In our case, the Qwen-VL-7B model proved stable and perfectly usable.
Key hyper-parameters in QLoRA
When using LoRA (Low-Rank Adaptation) for fine-tuner, the two main hyperparameters are : r and alpha.
r(rank) This parameter defines the decomposition rank used to approximate weight matrices. Instead of directly fitting a large matrix, LoRA learns two small matrices of size(d, r)and(r, d). Moreris higher, the greater the adaptability - but at the cost of a larger memory footprint, and greater overfit potential.alpha(scaling) This factor is used to adjust LoRA update intensity. In concrete terms, the update is multiplied byalpha / rbefore being added to the base model. This makes it possible to fine-tune the influence of LoRA, and avoid excessive disturbance of the pre-trained weights.
In a nutshell: r controls the wealth adaptation, alpha by regulating impact.
r = 8, # rang de la décomposition
lora_alpha = 16, # scaling
lora_dropout = 0.1
finetune_vision_layers = False, # vision déjà robuste
finetune_language_layers = True, # on adapte la partie texte
finetune_attention_modules = True,
finetune_mlp_modules = False # limite l’overfit sur petit jeu
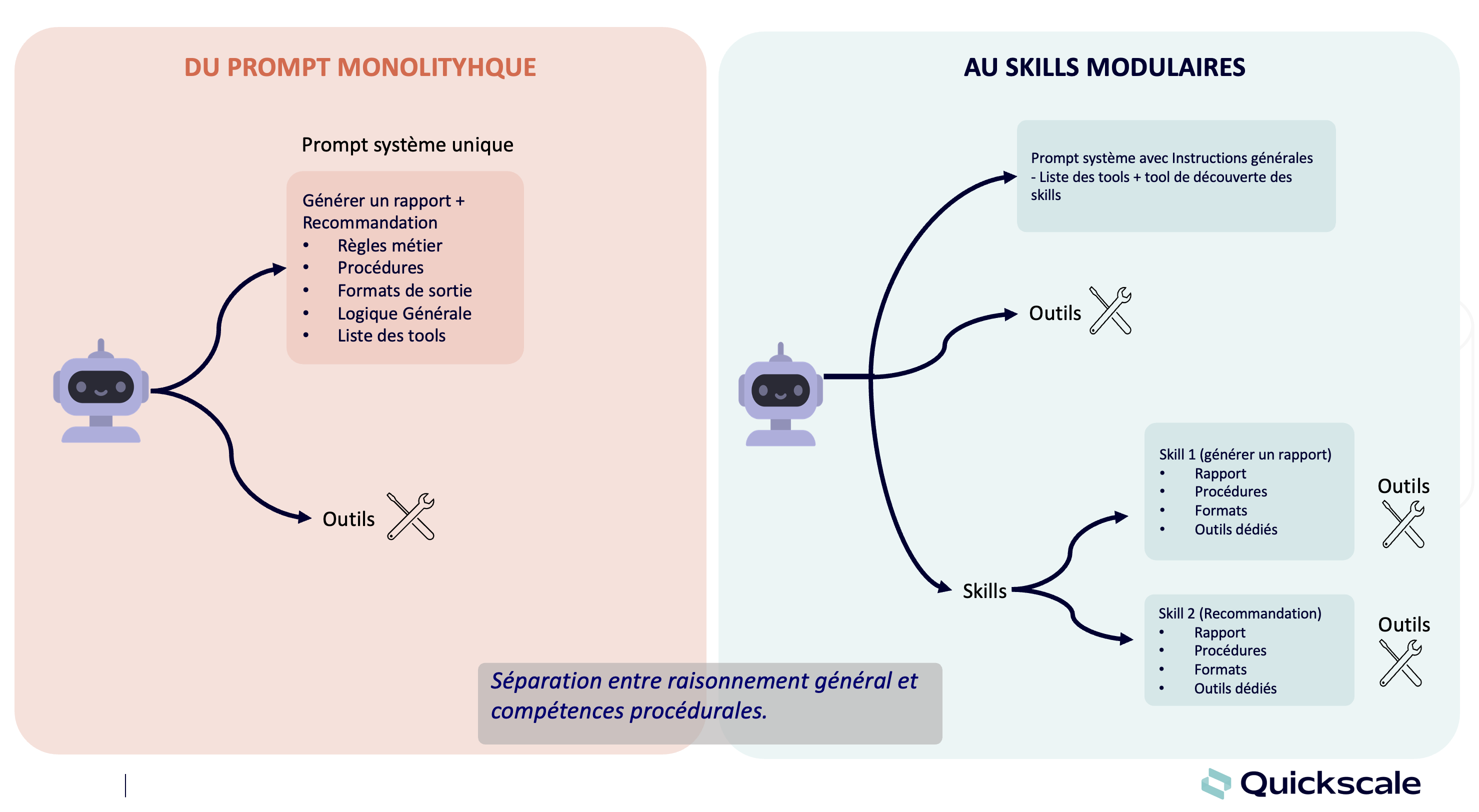
- Why no vision? CORD receipts resemble the images seen during pre-training; there's no need to re-train vision a priori.
- Why rank 8 / alpha 16? First test in
r=32/alpha=64→ overfit. Lowering LoRA capacity improves generalization (+14 pts overall score).
Data
For our dataset and our task, we opted for something classic: receipt parsing (the Cord-V2 dataset ). The images are very ordinary, but the output is interesting and justifies the use of a VLM. It's JSON that organizes the information in the receipt. Here's an example:
image:
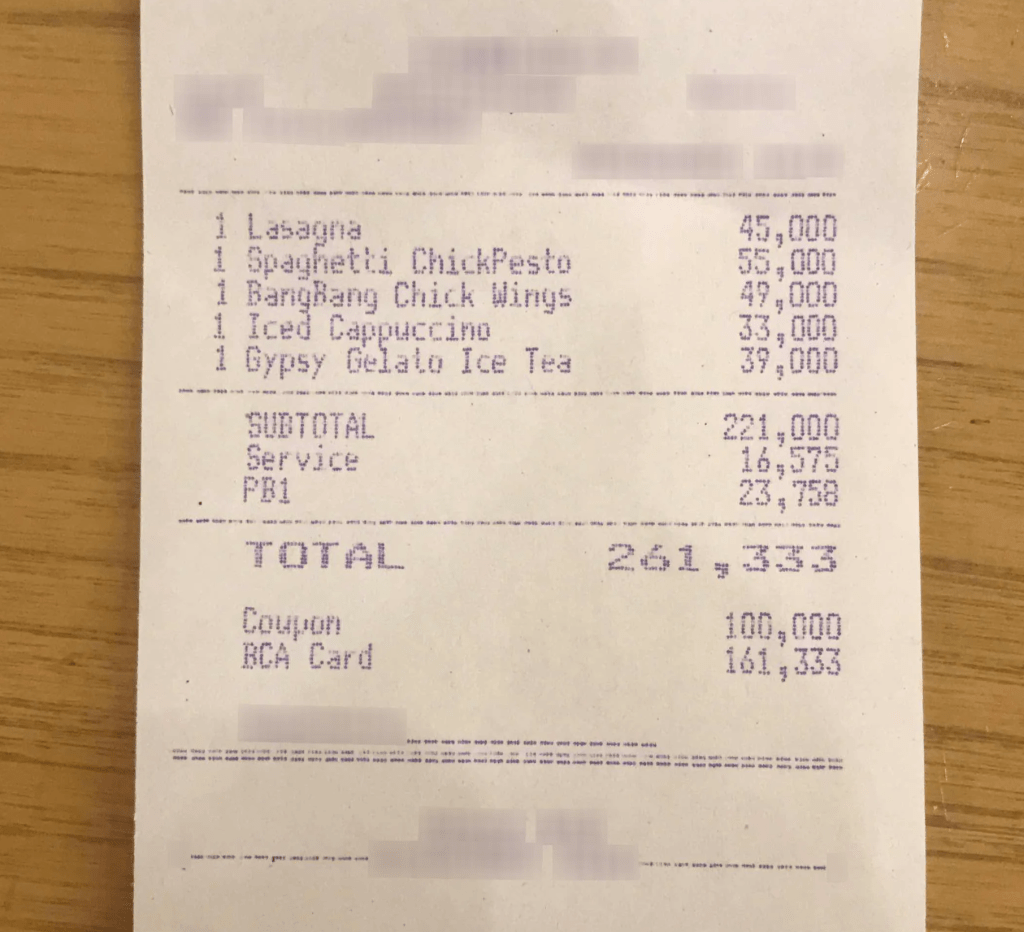
output:
{'menu': [
{'nm': 'Lasagna', 'cnt': '1', 'price': '45,000'},
{'nm': 'Spaghetti ChickPesto', 'cnt': '1', 'price': '55,000'},
{'nm': 'BangBang Chick Wings', 'cnt': '1', 'price': '49,000'},
{'nm': 'Iced Cappuccino', 'cnt': '1', 'price': '33,000'},
{'nm': 'Gypsy Gelato Ice Tea', 'cnt': '1', 'price': '39,000'}
],
'sub_total': {
'subtotal_price': '221,000',
'service_price': '16,575',
'tax_price': '23,758'
},
'total': {
'total_price': '261,333',
'total_etc': '100,000',
'creditcardprice': '161,333'
}
}
You also need to define a prompt for both inference AND training. Unless you're a Senior prompt engineer and manage to write the perfect prompt, your model will copy the example in the prompt to inference (at least, we haven't really managed to prevent this). So we opted for a short, direct prompt like:
instruction_prompt = """
Extract all the structured information available from the receipt.
### INSTRUCTIONS:
- Return **only** a valid JSON object.
- No extra words or explanations.
- If a section exists (e.g., subtotal, taxes, services), include it.
- If a section does not exist on the receipt, do not invent it.
- Use the following general structure:
- "menu": [ {"nm", "cnt", "price", ...} ]
- "sub_total": { ... }
- "total": { ... }
Start directly with your JSON:
"""
Training
For training, here are our parameters:
- batch size at 1
- gradient accumulation of 4 (to simulate a batch size of 4)
- Number of epochs at 2
- learning rate of 2e-4
- warmup_steps = 40 (to smooth initial learning)
- 8-bit AdamW optimizer (memory savings)
- cosine scheduler (smooth learning rate decay)
Duration
- Preparation time: 10 min
- Fine-tuning (2 epochs, batch 1, grad acc 4): ~55 min
- Inference test (100 images): 25 min
Backup and deployment
After waiting a little while, it's time to save the weights, but only the LoRA weights. This makes fine tuning exceptionally portable, since the LoRA weights weigh just a few MB:
# Pour sauvegarder en dur
model.save_pretrained("RUN NAME")
# Pour push vers hugging face hub
model.push_to_hub("USER" + "RUN NAME", token = "hg token") # meilleur pour le partage
You can reload your fine-tuned model like this:
# Charge le modèle de base + directement LoRA adapté
model, tokenizer = FastVisionModel.from_pretrained(
model_name = "unsloth/Qwen2-VL-7B-Instruct", # 👈 le modèle de base
adapter_name = "USER" + "RUN NAME", # 👈 le repo Hugging Face ou chemin local
load_in_4bit = True, # ou False si besoin
use_gradient_checkpointing = "unsloth", # ou True
)
Comparison with GPT-4o
We also inferred on the test set with GPT-4o for comparison. As the model is powerful enough to understand examples, we provided it with the same prompt, but with 2-3 examples.
Performance measurement on the test set
Performance evaluation of the receipt parsing task
To assess the quality of predictions generated by our vision-language model (VLM) on the CORD-V2 dataset, we have implemented a customized metric, adapted to the structured nature of the output. Each prediction takes the form of a JSON object representing the content of a receipt. The evaluation follows several complementary steps.
1. Checking JSON format
First of all, we check that the prediction is a valid JSON.
2. Comparison of main keys
We compare the dictionary's high-level keys (for example menu, sub_total, total) between prediction and ground truth :
- The "main keys" metric is 1 if the key sets are exactly the same, otherwise 0.
This measures how well the model has recognized the document's general structure.
3. Evaluation of sub-sections sub_total and total
For each sub-dictionary in the ground truth :
- We calculate a subkey accuracy (
subkeys_accuracy): proportion of correct keys found in the prediction. - We calculate a accuracy of values (
values_accuracy): proportion of correct values among keys shared between prediction and ground truth.
4. Field evaluation menu
The field menu contains a list of structured elements (dishes, quantities, prices, etc.). To evaluate the quality of predictions on this field, we proceed in three distinct steps:
- Matching dish names (
nm) For each element in the ground truth, we try to find an element in the prediction whose name is an approximate match (fuzzy matching with a similarity threshold of 85%). If a match is found, the name is considered to be well predicted. - Key accuracy (
menu__keys_accuracy) For each element correctly associated (by name), we measure how many secondary keys (likecnt,price,unitpriceetc.) are found. The proportion of ground truth keys present in the prediction is then calculated for each input. - Accuracy of values (
menu__values_accuracy) For common secondary keys between ground truth and prediction, we measure the proportion of exact values (strict equality).
5. Aggregation
To get a global view of the metrics, we've created global metrics from the previous ones: global menu, global subtotal, global total, which are simply the averages of the metrics associated with the menu, subtotal and total respectively. The "Global" metric is the average of all metrics.
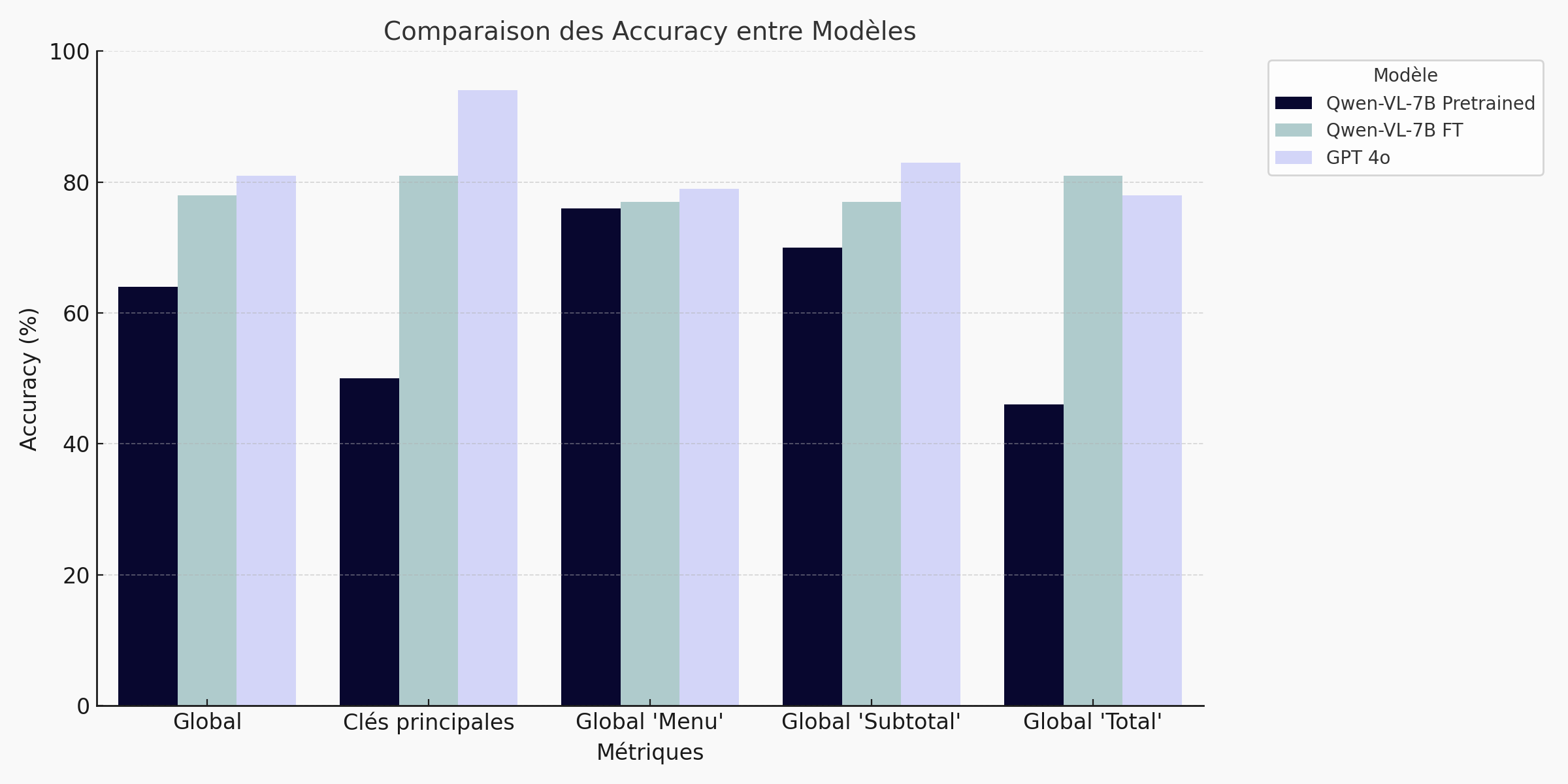
Results: 78% overall score
Bar chart - Summary of results:
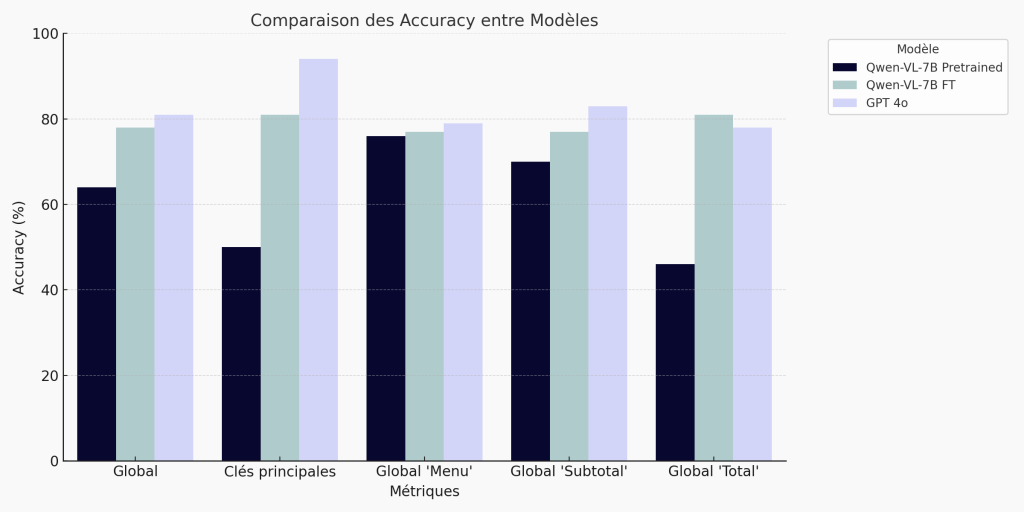
Table - Summary of results:

🔍 Fine-tuning the Qwen VL 7B model delivers a clear performance improvement on the receipt extraction task. The overall accuracy score rises from 64% (pre-trained) to 78%, reducing the gap with GPT-4o (81%) to just 3 points. The gains are particularly marked on structured fields such as totals (+35 pts) and main keys (+31 pts). This result shows that a well-adapted open-source model can compete with the market leaders on targeted business cases, while remaining lightweight, confidential and cost-effective.
For detailed results, please refer to the appendix.
When to choose GPT-4o?
Qlora + finetuning or GPT-4o are not competing solutions, but complementary ones. You simply have to choose according to these constraints, so as to maximize your ROI. To clarify matters, here's a summary table:

Conclusion & next steps
In less than an hour, using a standard T4 GPU, we have shown that an open-source VLM of intermediate size can compete with a model like GPT-4o on a targeted business task.
This type of approach combines :
- Portability
- Privacy
- Cost control
Next tracks:
- Test the generation of annotated PDFs directly from the template.
- Switch to LLaVA-Next-11B Vision to enlarge the image window.
- Explore LoRA + IA3 adapters to further reduce delta size.
At Quickscale.ai we work with you to leverage the models best suited to your business context - whether through localized fine-tuning, private deployment or optimized integration of general-purpose models.
Contact us to explore together what multimodal AI can concretely bring to your use cases: Contact
Appendix
Detailed results
| metric models | GPT-4o | Qwen VL 7B pre trained | Qwen VL 7B post fine tuning |
|---|---|---|---|
| Format | 100% | 100% | 100% |
| Main keys | 94% | 50% | 81% |
| Menu: | |||
| - name matching | 89.27% | 85.33% | 81.71% |
| - key accuracy | 80.74% | 81.31% | 80.39% |
| - accuracy of values | 68.86% | 61.59% | 68.46% |
| Subtotal: | |||
| - key accuracy | 91.26% (n=62)* | 91.67% (n=17)* | 91.17% (n=50)* |
| - accuracy of values | 74.73% (n=62)* | 50% (n=17)* | 64% (n=50)* |
| Total: | |||
| - key accuracy | 79.7% | 40.81% | 88.85% |
| - accuracy of values | 76.67% | 52% | 73.5% |
| Global | 81.9% | 64.09% | 78.63% |
*the "n" for subtotal indicates the number of observations for which we have calculated the metric. For example, as the Qwen Pretrained model correctly predicted the presence of the subtotal key 17 times out of 100, the corresponding metrics are calculated only from these 17 results, which may introduce a bias. For the rest, the "n" is not indicated because it is 100, i.e. the size of the dataset.
VRAM GPU
We have estimated the memory required for fine-tuning our model Qwen-VL-7B quantized to 4-bitwith LoRA and gradient accumulation (gradient_accumulation_steps = 4). Here are the details:
Quantized model (7B, 4-bit)
With 7 billion parameters encoded on 4 bits (i.e. 0.5 byte per parameter), the model occupies around 3.5 GB of memory.
LoRA adapters
We use 48 LoRA modules, with r = 8 and an input size of 4096. Counting the two matrices per module and a float32 encoding, this represents approximately 0.3 Go. After compression, the actual size is smaller, but we retain this estimate as a precaution.
Intermediate activations
The activations required for forward and backward passage are estimated using the classic formula :
0.5 × nb_layers × batch_size × hidden_size × seq_len × 4 / 1e9
With 32 layers, a hidden size of 4096, a sequence of 1024 tokens and a batch size of 1, this gives around 0.27 GB per pass. Since we're using 4-step accumulation, the memory dedicated to activations rises to around 1.07 GB.
CUDA overhead + temporary buffers
The memory automatically allocated by PyTorch, CUDA, attention caches or embedding buffers represents a significant share. We estimate it at around 3.5 GB.
Estimated total memory
3.5 GB (model) + 0.3 GB (LoRA) + 1.07 GB (activations) + 3.5 GB (overhead) = approx. 8.4 GB.
This configuration fits very comfortably on a 16 GB T4 GPU, with still enough margin to increase the batch size or even test a slightly larger model, like LLaMA Vision 11B, without memory saturation.
Our calculations are approximate. For a more accurate estimate, I highly recommend the site: vram-calculator to calculate the VRAM required for your use case.
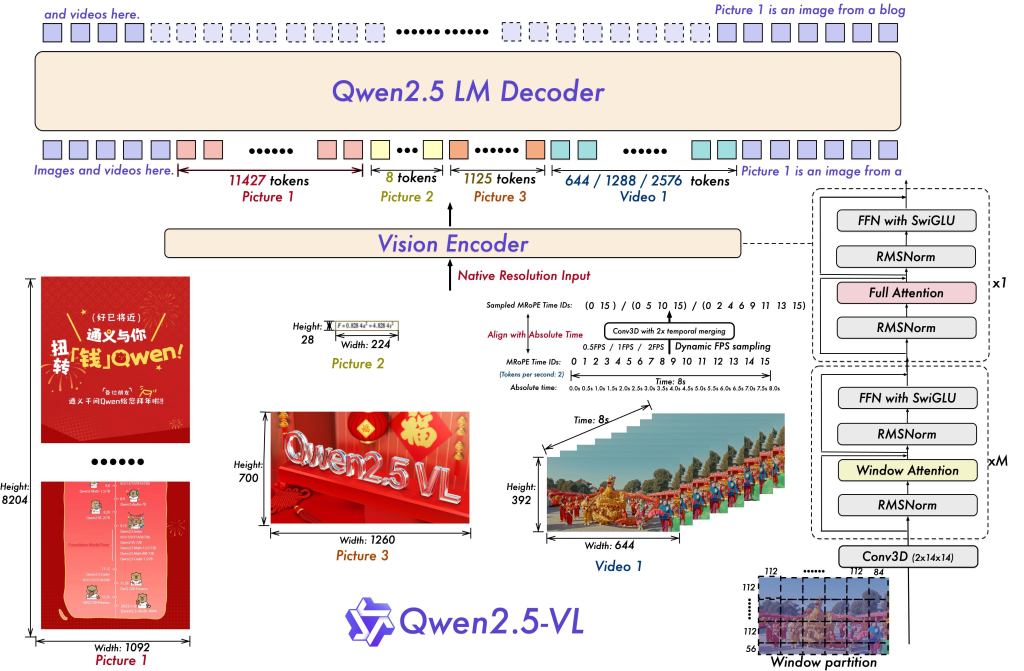
Qwen-VL
The Qwen-VL model is based on a Transformer decoder-only architecture, similar to that found in GPT-3 or LLaMA. Unlike approaches that process text and images separately, Qwen-VL directly integrates the two modalities into a single token sequence. Images are first processed by a CLIP ViT-L/14 Vision Transformer (ViT ), which transforms a 224×224 resolution image into a set of 16×16 patches, each of which is then encoded into a dense vector.
Once extracted, these vectors are projected into the language space via a projection MLP to match their visual dimension to that expected by the Qwen-7B model, i.e. 4096 dimensions. Each visual vector thus projected becomes a "visual token " inserted in the text sequence. The result is a sequence of tokens composed of both text and image - all in the same vector space, with the same structure.
This design enables direct concatenation of textual and visual tokens ([CLS], T1, T2, ..., V1, V2, ...) at the decoder input, without the need for a complex cross-attention mechanism. Everything is managed via standard self-attention, in a unified way. In this way, there is no distinction in processing between tokens from text and tokens from images: they participate together in the attentional dynamics of the model, in a native and homogeneous fusion.
To find out more about Qwen VL, here's their Github: QWEN VL Github
Read more: How to Fine tune a Vision Language Model in 1h on Colab for receipt extraction