Temps de lecture estimé: 12min
Les grands Visual Language Models (VLM) généralistes – GPT‑4o, Gemini 1.5 Pro… – savent déjà combiner texte et image. Pourtant, dans des contextes B2B régulés (financier, légal, assurance …), ils posent trois problèmes :
- Coût d’inférence élevé : déployer à grande échelle sur des flux massifs de documents pèse vite sur l’OPEX.
- Confidentialité : impossible d’envoyer systématiquement des documents sensibles vers le cloud d’un tiers.
- Spécificité métier : une facture coréenne ou un bail agricole impose une granularité que les modèles généralistes n’ont pas apprise.
Les VLM de taille intermédiaire (2 – 15 B paramètres) offrent un compromis : fine‑tunables, portables sur un GPU 16 Go et capables d’égaler (voire dépasser) les grands modèles sur des tâches très ciblées.
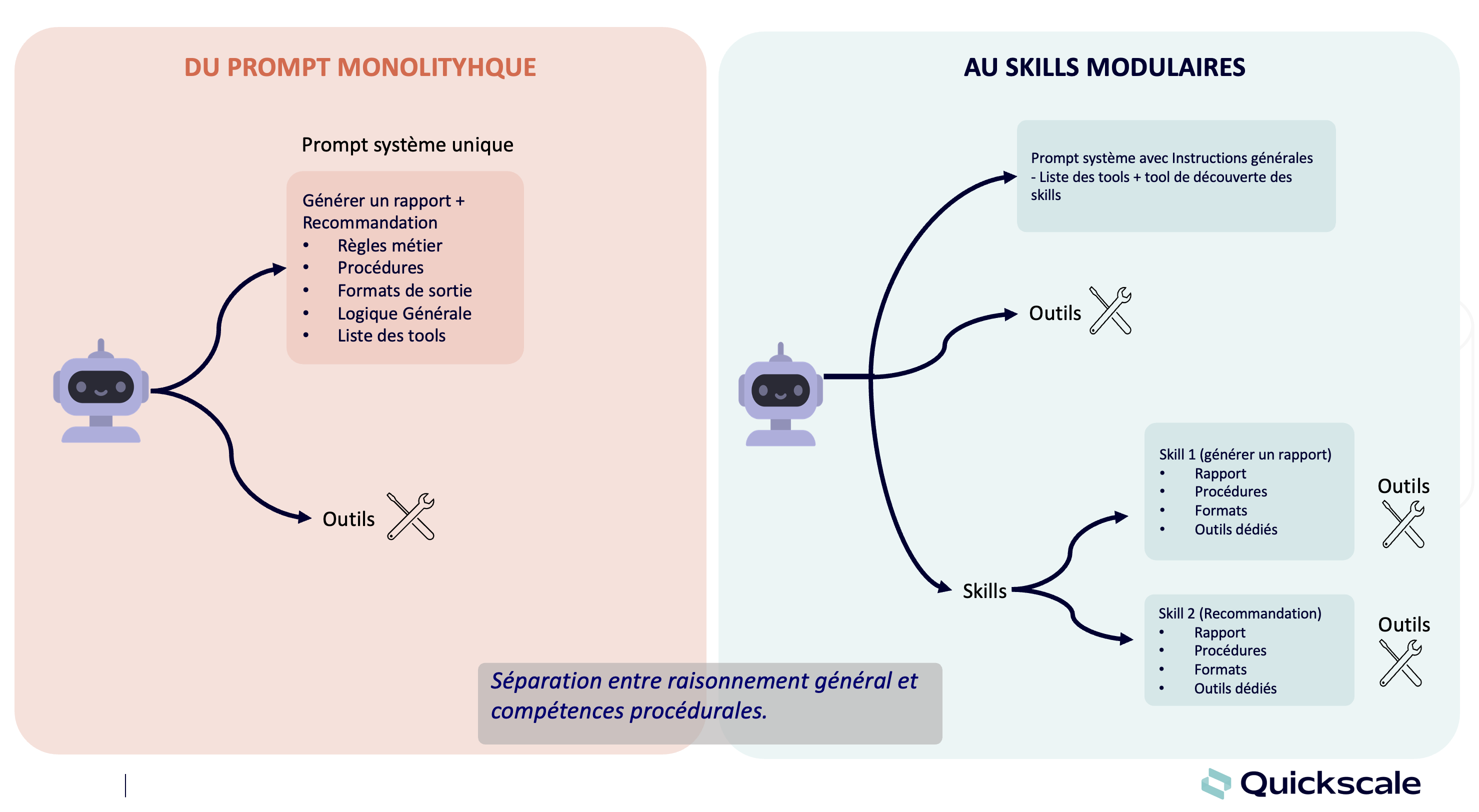
Cet article montre comment adapter un modèle open-source (Qwen-VL-7B-Instruct) à une tâche concrète : l’extraction d’informations structurées à partir de reçus (dataset CORD-V2).
Le tout, en moins d’une heure sur Google Colab, sans infrastructure lourde, et avec des performances proches de GPT‑4o.
Résumé
- Pourquoi des Small VLMs ? Les Visual Language Models de taille moyenne (2B–15B) permettent une adaptation fine à des cas métiers spécifiques tout en restant compatibles avec un GPU 16 Go, offrant un bon compromis entre performance, coût, et portabilité.
- Fine-tuning accessible et rapide En utilisant le framework Unsloth et un modèle quantifié (Qwen-VL-7B en 4-bit), le fine-tuning avec QLoRA peut se faire en moins d’une heure sur Google Colab.
- Résultats compétitifs Le modèle fine-tuned atteint des résultats très proche de GPT-4o.
- Cas d’usage démontré L’extraction structurée de reçus à partir d’images (dataset CORD-V2) démontre que ces VLMs sont adaptés aux tâches complexes multimodales
Setup : modèle, infrastructure, dataset
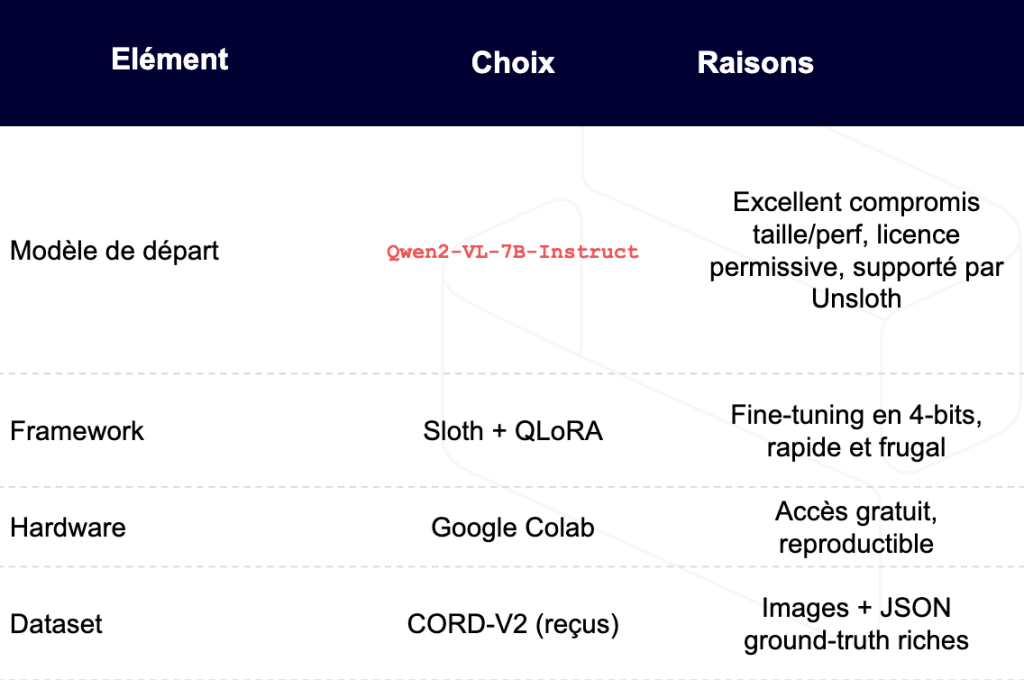
Nous allons vous montrer à partir d’un exemple la relative simplicité avec laquelle vous pouvez fine-tuner ce genre de modèle à bas coût, sans un gros hardware et sans entrainement interminable.
Pour notre exemple, notre choix s’est porté sur le modèle Qwen2-VL-7B-Instruct, un modèle open source chinois très performant. Pour une efficacité maximale, nous avons opté pour Unsloth, une bibliothèque légère permettant d’entraîner rapidement des modèles quantifiés en 4bits, dont notre modèle Qwen-VL-7B que nous fine tunerons ainsi en QLoRA (LoRA sur un modèle Quantizé).
Vous remarquerez que cette configuration tient amplement sur un GPU à 16 Go de RAM, ce qui est accessible gratuitement sur Google Colab!
Rentrons maintenant dans le vif du sujet : le code.
Fine-tuning en pratique
Nous sommes partis sur la base de ce notebook partagé par Unsloth: Unsloth Notebook fine tuning llama Vision
Et voici notre notebook Colab: VLM Finetuning notebook
Remarque sur Unsloth : le framework est encore en développement actif. Selon les modèles utilisés, vous pourriez rencontrer quelques instabilités (ex. : image non détectée ou réponse incohérente).
Dans notre cas, le modèle Qwen-VL-7B s’est montré stable et parfaitement exploitable.
Hyper-paramètres clés en QLoRA
Lorsque vous utilisez LoRA (Low-Rank Adaptation) pour fine-tuner, les deux prinicpaux hyperparamètres sont : r et alpha.
r(rank) : Ce paramètre définit le rang de la décomposition utilisée pour approximer les matrices de poids. Au lieu d’adapter directement une grande matrice, LoRA apprend deux petites matrices de taille(d, r)et(r, d). Plusrest élevé, plus la capacité d’adaptation est grande — mais au prix d’une empreinte mémoire plus importante, et d’une possibilité d’overfit accrue.alpha(scaling) : Ce facteur sert à ajuster l’intensité de la mise à jour LoRA. Concrètement, la mise à jour est multipliée paralpha / ravant d’être ajoutée au modèle de base. Cela permet de doser finement l’influence de LoRA, et d’éviter de perturber excessivement les poids préentraînés.
En résumé : r contrôle la richesse de l’adaptation, alpha en régule l’impact.
r = 8, # rang de la décomposition
lora_alpha = 16, # scaling
lora_dropout = 0.1
finetune_vision_layers = False, # vision déjà robuste
finetune_language_layers = True, # on adapte la partie texte
finetune_attention_modules = True,
finetune_mlp_modules = False # limite l’overfit sur petit jeu
- Pourquoi pas de vision ? Les reçus du CORD ressemblent aux images vues pendant le pré‑entraînement ; inutile de ré‑entraîner la vision a priori.
- Pourquoi rank 8 / alpha 16 ? Premier essai en
r=32/alpha=64→ overfit. En abaissant la capacité LoRA on améliore la généralisation (+14 pts en score global).
Data
Pour notre dataset et notre tâche, nous nous sommes orienté sur quelque chose de classique: le parsing de reçu (le dataset Cord-V2). Les images sont très ordinaires, cependant, l’output est intéressant et justifie bien l’utilisation d’un VLM. Il s’agit de JSON qui organise les informations du reçu. En voici, un exemple:
image:
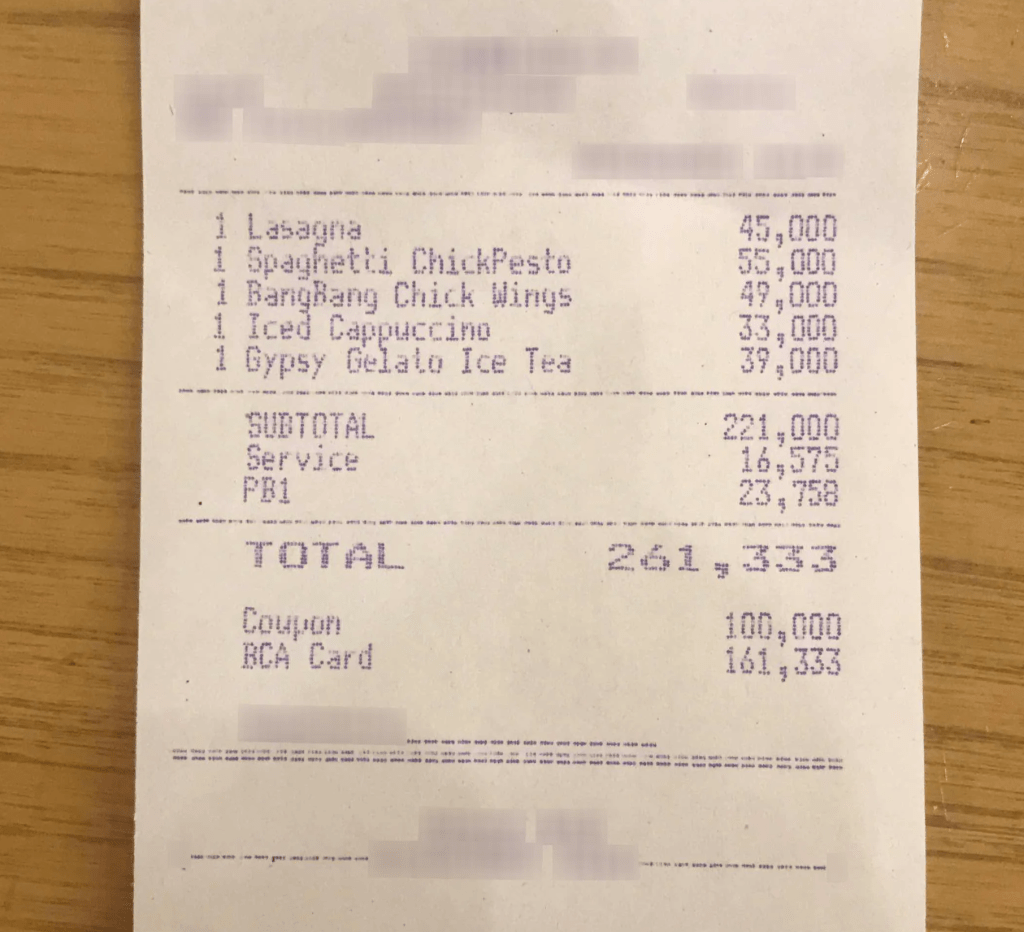
output:
{'menu': [
{'nm': 'Lasagna', 'cnt': '1', 'price': '45,000'},
{'nm': 'Spaghetti ChickPesto', 'cnt': '1', 'price': '55,000'},
{'nm': 'BangBang Chick Wings', 'cnt': '1', 'price': '49,000'},
{'nm': 'Iced Cappuccino', 'cnt': '1', 'price': '33,000'},
{'nm': 'Gypsy Gelato Ice Tea', 'cnt': '1', 'price': '39,000'}
],
'sub_total': {
'subtotal_price': '221,000',
'service_price': '16,575',
'tax_price': '23,758'
},
'total': {
'total_price': '261,333',
'total_etc': '100,000',
'creditcardprice': '161,333'
}
}
Il faut également définir un prompt à la fois pour l’inférence ET l’entrainement. A moins que vous soyez un Senior prompt engineer et que vous réussissiez à écrire le prompt parfait, votre modèle va recopier à l’inférence l’exemple présent dans le prompt (en tout cas, nous n’avons pas vraiment réussi à empêcher cela). Nous avons ainsi opté pour un prompt court et direct comme:
instruction_prompt = """
Extract all the structured information available from the receipt.
### INSTRUCTIONS:
- Return **only** a valid JSON object.
- No extra words or explanations.
- If a section exists (e.g., subtotal, taxes, services), include it.
- If a section does not exist on the receipt, do not invent it.
- Use the following general structure:
- "menu": [ {"nm", "cnt", "price", ...} ]
- "sub_total": { ... }
- "total": { ... }
Start directly with your JSON:
"""
Training
Pour le training, voici nos paramètres:
- taille des batch à 1
- accumulation de gradients à 4 (pour simuler un batch size de 4)
- Nombres d’épochs à 2
- learning rate de 2e-4
- warmup_steps = 40 (pour lisser l’apprentissage initial)
- optimiseur AdamW en 8-bit (économie mémoire)
- scheduler de type cosinus (décroissance douce du learning rate)
Durée
- Préparation données : 10 min
- Fine‑tuning (2 epochs, batch 1, grad acc 4) : ~55 min
- Inférence test (100 images) : 25 min
Sauvegarde et déploiement
Après avoir patienté un petit moment, il faut sauver les poids, mais seulement les poids LoRA. Cela rend le fine tuning exceptionnellement portable, puisque les poids LoRA pèsent quelques Mo:
# Pour sauvegarder en dur
model.save_pretrained("RUN NAME")
# Pour push vers hugging face hub
model.push_to_hub("USER" + "RUN NAME", token = "hg token") # meilleur pour le partage
Vous pouvez reload votre modèle fine tuned comme ceci:
# Charge le modèle de base + directement LoRA adapté
model, tokenizer = FastVisionModel.from_pretrained(
model_name = "unsloth/Qwen2-VL-7B-Instruct", # 👈 le modèle de base
adapter_name = "USER" + "RUN NAME", # 👈 le repo Hugging Face ou chemin local
load_in_4bit = True, # ou False si besoin
use_gradient_checkpointing = "unsloth", # ou True
)
Comparaison avec GPT-4o
Nous avons également inféré sur le jeu de test avec GPT-4o afin d’avoir une comparaison. Comme le modèle est assez puissant pour comprendre les exemples, nous lui avons fourni le même prompt, mais avec 2-3 exemples.
Mesure des performances sur le jeu de test
Évaluation des performances sur la tâche de parsing de reçus
Pour évaluer la qualité des prédictions générées par notre modèle vision-langage (VLM) sur le dataset CORD-V2, nous avons mis en place une métrique sur mesure, adaptée à la nature structurée des sorties. Chaque prédiction prend la forme d’un objet JSON représentant le contenu d’un reçu. L’évaluation suit plusieurs étapes complémentaires.
1. Vérification du format JSON
Avant toute chose, on vérifie que la prédiction est bien un JSON valide.
2. Comparaison des clés principales
On compare les clés de haut niveau du dictionnaire (par exemple menu, sub_total, total) entre la prédiction et le ground truth :
- La métrique ”clés principales” vaut 1 si les ensembles de clés sont exactement les mêmes, sinon 0.
Cela permet de mesurer si le modèle a bien reconnu la structure générale du document.
3. Évaluation des sous-sections sub_total et total
Pour chaque sous-dictionnaire présent dans le ground truth :
- On calcule une accuracy des sous-clés (
subkeys_accuracy) : proportion des bonnes clés retrouvées dans la prédiction. - On calcule une accuracy des valeurs (
values_accuracy) : proportion des bonnes valeurs parmi les clés partagées entre la prédiction et le ground truth.
4. Évaluation du champ menu
Le champ menu contient une liste d’éléments structurés (plats, quantités, prix, etc.). Pour évaluer la qualité des prédictions sur ce champ, on procède en trois étapes distinctes :
- Matching des noms de plats (
nm) : Pour chaque élément du ground truth, on tente de trouver un élément de la prédiction dont le nom correspond de manière approximative (fuzzy matching avec un seuil de similarité de 85 %). Si une correspondance est trouvée, on considère que le nom est bien prédit. - Exactitude des clés (
menu__keys_accuracy) : Pour chaque élément correctement associé (par nom), on mesure combien de clés secondaires (commecnt,price,unitprice, etc.) sont retrouvées. On calcule alors, pour chaque entrée, la proportion de clés du ground truth présentes dans la prédiction. - Exactitude des valeurs (
menu__values_accuracy) : Pour les clés secondaires communes entre ground truth et prédiction, on mesure la proportion de valeurs exactes (égalité stricte).
5. Agrégation
Pour avoir une vue globale sur les métriques, nous avons créé des métriques globales à partir des précédentes: global menu, global subtotal, global total qui sont simplement les moyennes des métriques associées respectivement au menu, au subtotal et au total. La métrique “Global” est la moyenne de toutes les métriques.
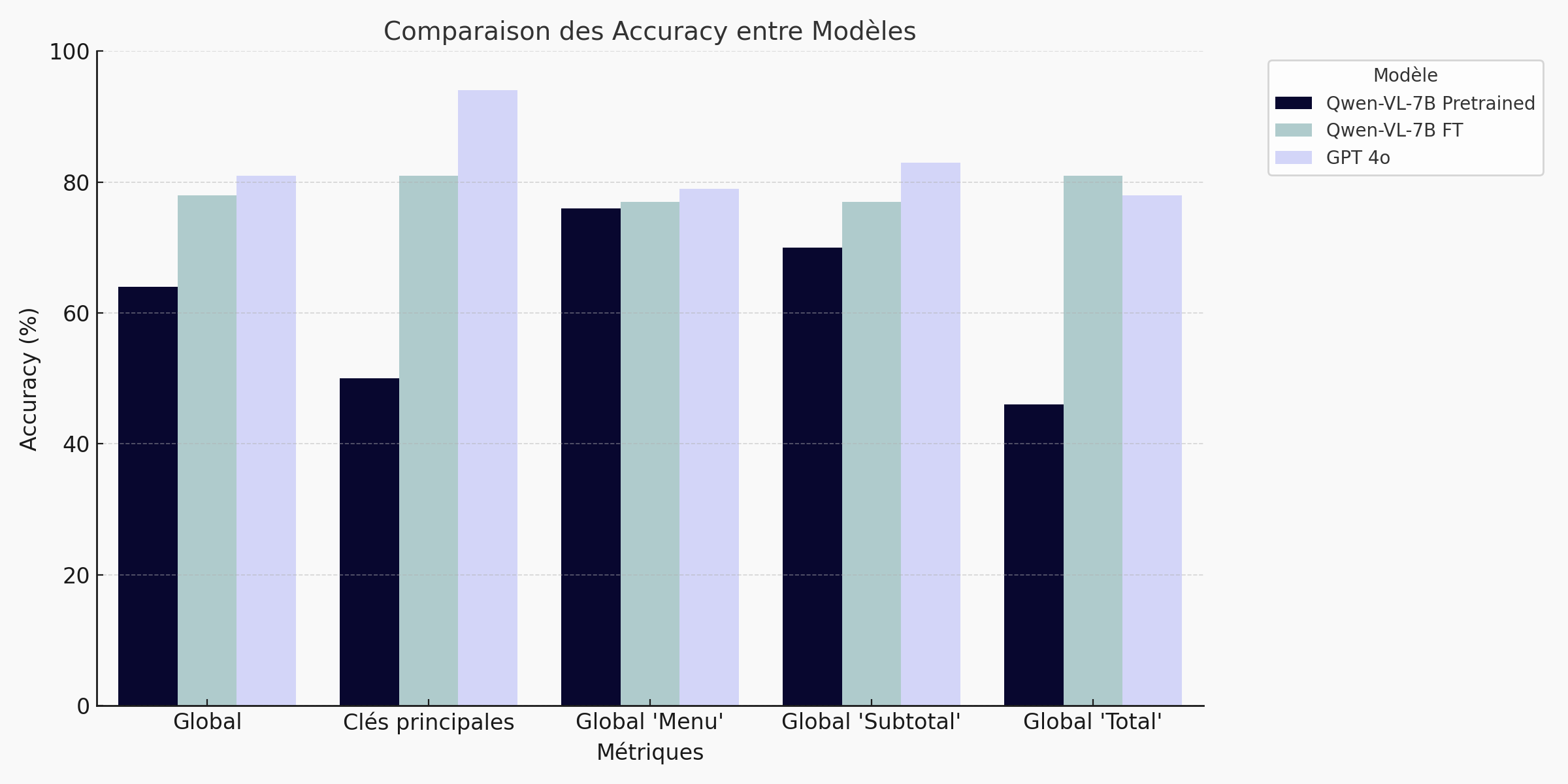
Résultats: 78 % de score global
Diagramme en barres – Synthèse des résultats:
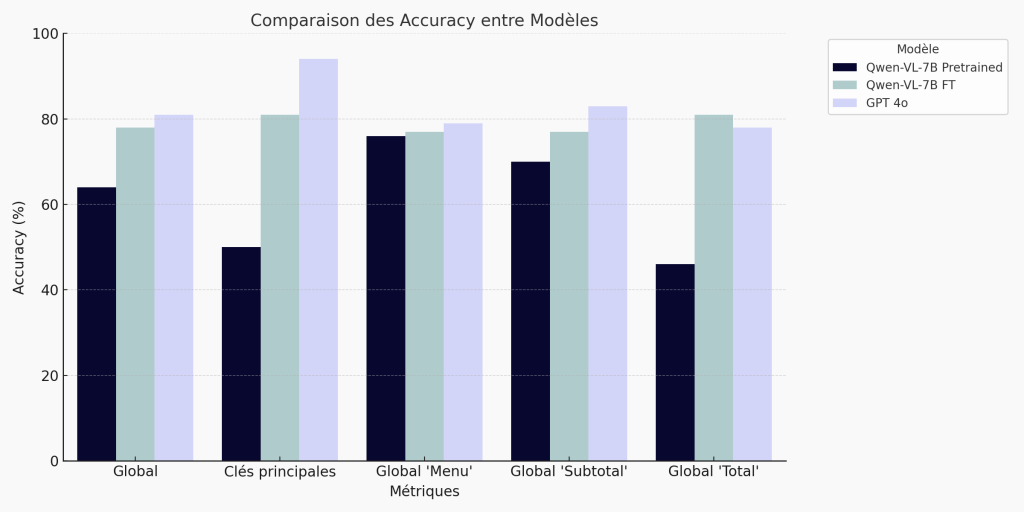
Tableau – Synthèse des résultats:

🔍 Le fine-tuning du modèle Qwen VL 7B permet une nette amélioration des performances sur la tâche d’extraction de reçus. Le score d’accuracy global passe de 64 % (pré-entraîné) à 78 %, réduisant l’écart avec GPT‑4o (81 %) à seulement 3 points. Les gains sont particulièrement marqués sur les champs structurés comme les totaux (+35 pts) et les clés principales (+31 pts). Ce résultat montre qu’un modèle open-source bien adapté peut rivaliser avec les leaders du marché sur des cas métier ciblés, tout en restant léger, confidentiel et économique.
Pour le détail des résultats, vous pouvez vous référer à l’annexe.
Quand préférer GPT-4o ?
Les solutions Qlora + finetuning ou GPT-4o ne sont pas concurrentes mais complémentaires. Il faut simplement choisir selon ces contraintes, de façon à maximiser son ROI. Pour y voir clair, voici un tableau récapitulatif:

Conclusion & next steps
En moins d’une heure, avec un GPU T4 standard, nous avons montré qu’un VLM open-source de taille intermédiaire peut rivaliser avec un modèle comme GPT‑4o sur une tâche métier ciblée.
Ce type d’approche combine :
- Portabilité
- Confidentialité
- Coût maîtrisé
Prochaines pistes :
- Tester la génération de PDF annotés directement depuis le modèle.
- Passer à LLaVA‑Next‑11B Vision pour élargir la fenêtre d’image.
- Explorer les adapters LoRA + IA3 pour réduire encore la taille des deltas.
Chez Quickscale.ai , nous vous accompagnons pour tirer parti des modèles les plus adaptés à votre contexte métier — que ce soit par du fine-tuning localisé, du déploiement privé ou une intégration optimisée de modèles généralistes.
Annexe
Détail des résultats
| métriques \ modèles | GPT-4o | Qwen VL 7B pre trained | Qwen VL 7B post fine tuning |
|---|---|---|---|
| Format | 100% | 100% | 100% |
| Clés principales | 94% | 50% | 81% |
| Menu: | |||
| – matching des noms | 89.27% | 85.33% | 81.71% |
| – accuracy des clés | 80.74% | 81.31% | 80.39% |
| – accuracy des valeurs | 68.86% | 61.59% | 68.46% |
| Subtotal: | |||
| – accuracy des clés | 91.26% (n=62)* | 91.67% (n=17)* | 91.17% (n=50)* |
| – accuracy des valeurs | 74.73% (n=62)* | 50% (n=17)* | 64% (n=50)* |
| Total: | |||
| – accuracy des clés | 79.7% | 40.81% | 88.85% |
| – accuracy des valeurs | 76.67% | 52% | 73.5% |
| Global | 81.9% | 64.09% | 78.63% |
*le “n” pour le subtotal indique le nombre d’observations pour lesquelles nous avons calculé la métrique. Par exemple, comme le modèle Qwen Pretrained a correctement prédit la présence de la clé subtotal 17 fois sur les 100, les métriques correspondantes sont calculés uniquement à partir de ces 17 résultats, ce qui peut introduire un biais. Pour le reste, le “n” n’est pas indiqué car il vaut 100, soit la taille du dataset.
VRAM GPU
Nous avons estimé la mémoire nécessaire au fine-tuning de notre modèle Qwen-VL-7B quantifié en 4-bit, avec LoRA et accumulation de gradient (gradient_accumulation_steps = 4). Voici le détail :
Modèle quantifié (7B, 4-bit)
Avec 7 milliards de paramètres encodés sur 4 bits (soit 0,5 byte par paramètre), le modèle occupe environ 3,5 Go de mémoire.
Adaptateurs LoRA
Nous utilisons 48 modules LoRA, avec r = 8 et une taille d’entrée de 4096. En comptant les deux matrices par module et un encodage en float32, cela représente environ 0,3 Go. Après compression, la taille réelle est moindre, mais nous conservons cette estimation par prudence.
Activations intermédiaires
Les activations nécessaires pour le passage forward et backward sont estimées avec la formule classique :
0.5 × nb_layers × batch_size × hidden_size × seq_len × 4 / 1e9
Avec 32 couches, une taille cachée de 4096, une séquence de 1024 tokens et un batch size de 1, cela donne environ 0,27 Go par passage. Comme nous utilisons une accumulation sur 4 steps, la mémoire dédiée aux activations monte à environ 1,07 Go.
Overhead CUDA + buffers temporaires
La mémoire allouée automatiquement par PyTorch, CUDA, les caches d’attention ou les buffers liés aux embeddings représente une part significative. Nous l’estimons ici à environ 3,5 Go.
Mémoire totale estimée
3,5 Go (modèle) + 0,3 Go (LoRA) + 1,07 Go (activations) + 3,5 Go (overhead) = environ 8,4 Go.
Cette configuration tient très confortablement sur une GPU T4 de 16 Go, avec encore une marge suffisante pour augmenter le batch size ou même tester un modèle légèrement plus gros, comme LLaMA Vision 11B, sans saturation mémoire.
Nos calculs sont approximatifs. Pour un estimation plus fine, je vous recommande grandement le site: vram-calculator pour calculer la VRAM nécessaire pour votre cas d’usage.
Qwen-VL
Le modèle Qwen-VL repose sur une architecture de type Transformer decoder-only, à l’image de ce que l’on retrouve chez GPT-3 ou LLaMA. Contrairement aux approches qui traitent séparément le texte et l’image, Qwen-VL intègre directement les deux modalités dans une même séquence de tokens. Les images sont d’abord traitées par un Vision Transformer (ViT) de type CLIP ViT-L/14, qui transforme une image de résolution 224×224 en un ensemble de patches de 16×16, chacun étant ensuite encodé en un vecteur dense.
Une fois extraits, ces vecteurs sont projetés dans l’espace du langage via une MLP de projection afin de faire correspondre leur dimension visuelle avec celle attendue par le modèle Qwen-7B, soit 4096 dimensions. Chaque vecteur visuel ainsi projeté devient un “visual token” inséré dans la séquence textuelle. On obtient donc une suite de tokens composée à la fois de texte et d’image — tous dans le même espace vectoriel, avec la même structure.
Ce design permet une concaténation directe des tokens textuels et visuels ([CLS], T1, T2, …, V1, V2, …) en entrée du décodeur, sans recourir à un mécanisme complexe de type cross-attention. Tout est géré via la self-attention standard, de façon unifiée. Il n’y a ainsi aucune distinction dans le traitement entre les tokens issus du texte et ceux issus des images : ils participent ensemble à la dynamique attentionnelle du modèle, dans une fusion native et homogène.
Pour en savoir plus sur Qwen VL, voici leur Github: QWEN VL Github
Read more: Comment Fine tune un Vision Language Model en 1h sur Colab pour l’extraction de reçus