L’essor des agents autonomes ne repose plus uniquement sur la puissance de calcul brute des LLMs, mais aussi sur une architecture de gestion de l’information de plus en plus sophistiquée. En 2026, la frontière entre un simple chatbot et un véritable système agentique se situe souvent dans la capacité à retenir, traiter et oublier l’information de manière stratégique.
Pour un développeur, concevoir un agent efficace inclut souvent bâtir un système de mémoire multi-niveaux. Cette évolution est dictée par une réalité technique : malgré l’extension massive des fenêtres de contexte (atteignant désormais 1 million de tokens pour Gemini 1.5 Pro et Claude 4.6), “tout injecter” dans le contexte reste une stratégie coûteuse et souvent source de confusion pour le modèle car ça exige plus de tokens et de mémoire.
Les géants du secteur ont chacun apporté leur réponse à ce défi :
- Anthropic a introduit le concept de “Context Compaction“, permettant à ses modèles Claude de résumer leur propre historique pour libérer de l’espace tout en préservant l’essentiel.
- OpenAI, via son Agents SDK, propose une architecture de mémoire basée sur des sessions pouvant être reliées à différents backends de stockage, permettant à un agent de conserver et réutiliser son historique de conversation au-delà d’une seule exécution. Pour une mémoire sémantique ou personnalisée à long terme entre sessions, des couches externes restent nécessaires. (voir ici)
- Google, avec ses recherches sur les architectures comme Titans et le cadre MIRAS, explore des modèles qui introduisent des mécanismes de mémoire adaptative capables de mettre à jour leur mémoire interne en temps réel durant l’inférence, ce qui permet une gestion plus fluide des informations tout au long du traitement d’une séquence (voir ici)
Dans cet article, nous explorerons comment ces différents niveaux de mémoire (du stimuli externe au stockage sémantique à long terme) s’articulent pour équiper des agents des stratégies de mémorisation adaptées et efficaces.
1. Les différents niveaux de mémoire
Dans l’écosystème actuel de l’IA, la mémoire n’est plus perçue comme un simple disque dur statique, mais comme un système dynamique d’accès à l’information, selon différents mécanismes. Deux strates fondamentales de la mémoire agentique ont progressivement émergé dans la pratique : la mémoire à court terme et la mémoire à long terme.
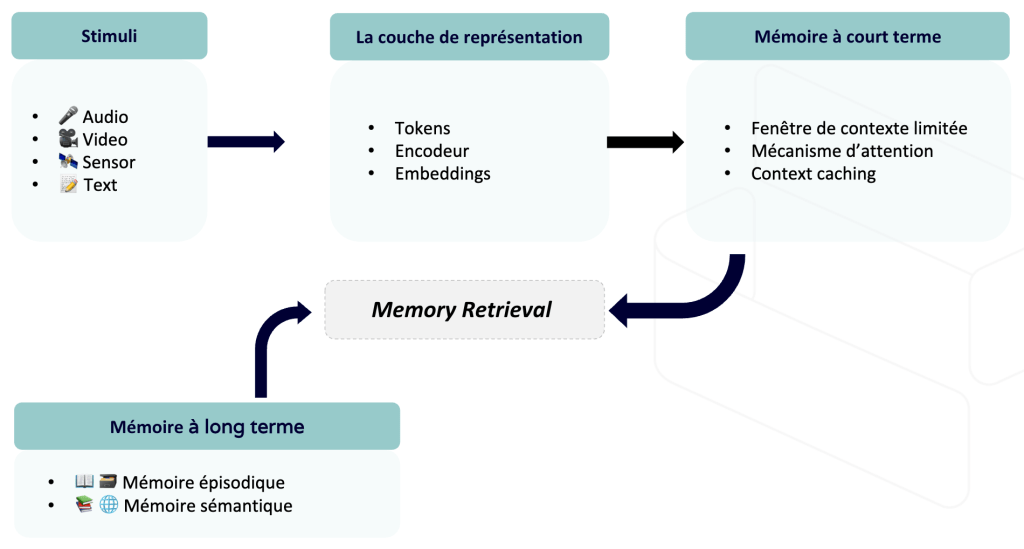
Avant d’être traitées par l’agent et ses modèles, les entrées (texte, images, audio) sont converties en embeddings via des couches spécialisées. Ces vecteurs numériques servent de représentations exploitables et sont intégrés directement dans la mémoire à court terme (fenêtre de contexte, KV cache) pour le raisonnement de l’agent.
Mémoire à court terme
Aussi appelée mémoire de travail, elle réside dans la fenêtre de contexte de l’agent. C’est l’espace de calcul actif où l’IA maintient la cohérence de la conversation et déploie ses capacités de raisonnement (notamment via le Chain-of-Thought ou l’inférence par étapes).
Cet espace de stockage évolue dynamiquement au cours de la conversation. Il contient les instructions données au modèle (le system prompt), et l’historique de la conversation. Par défaut, il n’est pas partagé entre plusieurs conversations.
Si une conversation se prolonge, ou si trop d’informations y sont échangées, la taille du contexte peut grandir dans des proportions qui mènent à une dilution de contexte (phénomène “Lost in the Middle”). Le mécanisme de compaction permet de réduire la taille du contexte, tout en conservant les informations-clé.
À côté de ces mécanismes de gestion du contexte, certaines infrastructures introduisent également des optimisations d’inférence, comme le context caching, qui permet de réutiliser des segments de contexte déjà traités afin de réduire la latence et les coûts lorsque de longs préfixes sont répétés.
Malgré des fenêtres atteignant désormais plusieurs millions de tokens, cette mémoire demeure intrinsèquement volatile. Contrairement aux poids du modèle ou à une base de données vectorielle (RAG), l’information n’est pas persistante; elle est perdue à la clôture de la session. Ceci dit, il est possible de concevoir des mécanismes de sauvegarde dans la mémoire à long terme.
Mémoire à long terme
Pour qu’un agent soit réellement utile sur la durée, il doit posséder une Long-Term Memory capable de survivre à la fin d’une session. Elle se divise classiquement en trois catégories inspirées des travaux de Park et al. (2023) :
- Mémoire épisodique : un répertoire structuré d’expériences spécifiques et contextualisées, correspondant à des événements passés rencontrés par l’agent (actions, observations et résultats) et généralement associés à des métadonnées temporelles et contextuelles. Elle permet la récupération d’épisodes antérieurs afin de soutenir un raisonnement fondé sur l’expérience, notamment dans des mécanismes de case-based reasoning, d’adaptation comportementale ou de prise de décision informée par l’historique des interactions
- Mémoire sémantique : un réservoir de connaissances abstraites et généralisées contenant des faits, des concepts, des relations et des règles indépendants de tout événement particulier. Elle permet à l’agent de raisonner à partir de connaissances déclaratives générales ou le domaine d’application (ex. préférences utilisateur généralisées, structures de données, ontologies).
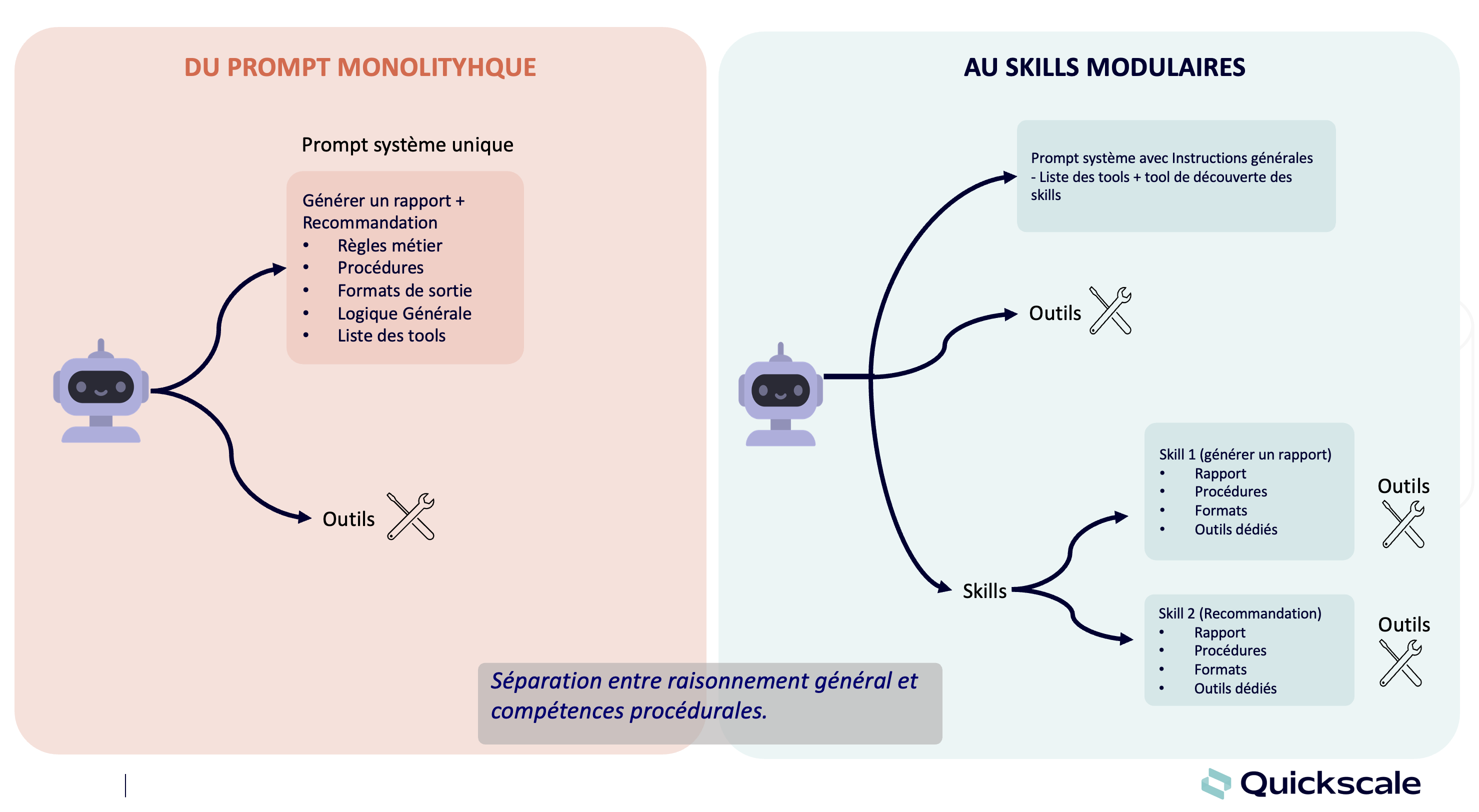
- Mémoire procédurale : ensemble de connaissances opératoires encodant les compétences, stratégies d’exécution, patterns d’utilisation d’outils et procédures d’action mobilisées par l’agent pour accomplir des tâches. Elle correspond à un savoir-faire (know-how) implémenté sous forme de règles décisionnelles, heuristiques, plans ou séquences d’opérations réutilisables, souvent intégrées dans les poids du modèle, les prompts système ou la logique de l’agent. Cette mémoire permet l’exécution efficace de tâches récurrentes en guidant le comportement de l’agent sans nécessiter un raisonnement explicite complet à chaque occurrence.
Implémentation : dans les architectures d’agents IA modernes, la mémoire procédurale encode le savoir‑faire de l’agent sous forme de politiques d’action, workflows, plans ou compétences réutilisables, tandis que la mémoire sémantique et épisodique est souvent stockée dans des bases de données vectorielles (RAG). Il est aussi possible d’utiliser des graphes de mémoire permettant une récupération granulaire d’informations pertinentes.
Le schéma ci-dessous montre une architecture mémoire pour un système RAG.
2. Utilité et scénarios d’application
Dans une architecture d’agent moderne, la gestion de la mémoire n’est pas une simple question de stockage, mais d’arbitrage. Chaque strate doit être sollicitée de manière sélective pour équilibrer trois facteurs critiques : la latence, le coût des tokens, la qualité (l’accuracy, précision et pertinence) des outputs de l’agent.
Mémoire procédurale : le réflexe opérationnel
Dans l’exemple suivant, la mémoire procédurale permet à l’agent d’appliquer des routines et stratégies réutilisables pour réagir automatiquement à des situations récurrentes.
- Scénario : drone agricole autonome surveillant ses cultures.
- Application : l’agent ne se contente pas de traiter les images brutes à 30 images par seconde. Sa mémoire procédurale contient des workflows prédéfinis :
- Détecter un parasite ou un début d’incendie dans le flux vidéo.
- Générer un “token d’alerte” contenant uniquement l’information clé.
- Déclencher un protocole de notification ou d’intervention.
Grâce à cette mémoire, l’agent peut agir automatiquement et de façon répétable, sans recalculer chaque étape depuis zéro. L’efficacité repose sur la capacité à appliquer des routines stables tout en filtrant le bruit, ce qui économise à la fois la latence, le coût des tokens et réduit la complexité cognitive de l’agent.
Mémoire à court terme : le bureau de raisonnement
Dans l’exemple suivant, la mémoire à court terme permet à l’agent de maintenir et manipuler activement les informations nécessaires pour le raisonnement immédiat.
- Scénario : agent de développement logiciel (ex: Devin ou GitHub Copilot Workspace).
- Application : lors d’une session de débogage, l’agent doit maintenir active la structure de votre base de code actuelle et vos dernières modifications. La mémoire à court terme permet d’exécuter un Chain-of-Thought (CoT) performant : l’agent pose une hypothèse, teste un correctif et analyse le log d’erreur, le tout en gardant ces étapes “en tête”. Si cette mémoire sature, l’agent peut perdre le fil de sa propre logique de résolution, d’où l’idée d’étendre avec des mémoires persistantes.
Mémoire épisodique : la continuité relationnelle
Dans l’exemple suivant, la mémoire épisodique permet à l’agent de se souvenir d’interactions spécifiques et de leur contexte, pour simuler une expérience vécue.
- Scénario : assistant de gestion de projet IA.
- Application : “lundi dernier, vous aviez rejeté cette option budgétaire parce qu’elle dépassait les coûts marketing.” Contrairement à une simple base de données, la mémoire épisodique capture le contexte temporel et émotionnel. En 2026, des frameworks comme Mem0 ou Letta permettent aux agents de réaliser des “Checkpoints” de ces épisodes, assurant que l’agent évolue avec vous au fil des semaines sans repartir de zéro à chaque session.
Mémoire sémantique : le savoir encyclopédique via RAG
Dans l’exemple suivant, la mémoire sémantique permet à l’agent de consulter et utiliser des connaissances générales ou spécialisées en temps réel, au-delà de ce qui a été appris lors de son entraînement initial.
- Scénario : agent de conformité bancaire internationale.
- Application : face à une nouvelle régulation, l’agent n’a pas besoin d’être ré-entraîné. Il interroge sa base de données vectorielle (mémoire sémantique), extrait les articles de loi pertinents et les injecte dans son raisonnement. C’est la garantie d’une expertise technique toujours à jour, traçable et sourcée, minimisant ainsi les risques d’hallucinations factuelles moyennant la fréquence à laquelle on ingère & indexe les données.
Un workflow d’utilisation de la mémoire dans l’agent est schématisée ci-dessous. Il faut noter que les étapes 03, 04, 05 et 06 dépendent de l’implémentation de l’agent et l’ordre de leur réalisation peut changer. Ce scénario illustre différentes possibilités offertes par les différents mémoires.
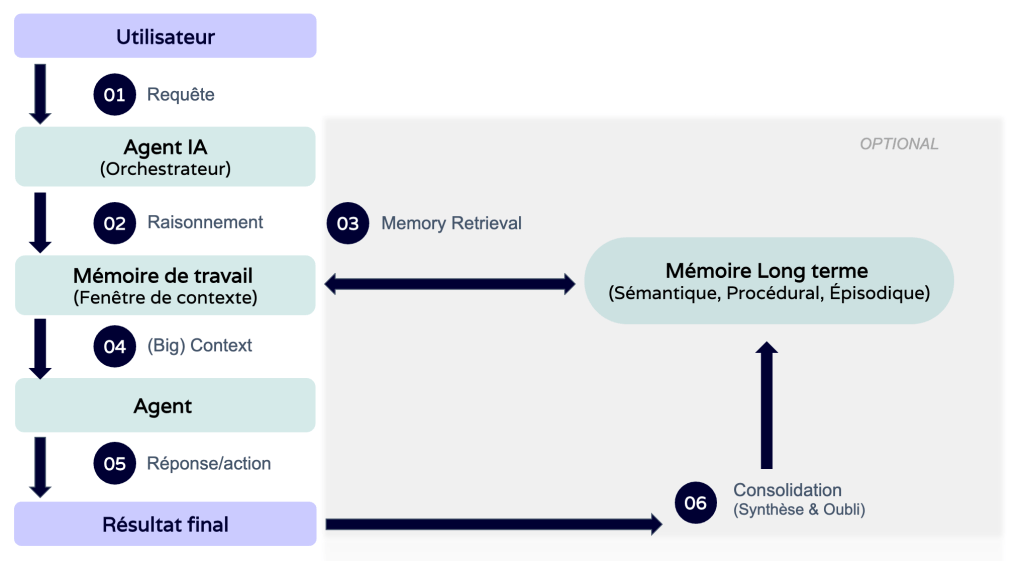
3. Implémentation
Pour qu’un agent coordonne plusieurs types de mémoire de manière efficace, il faut une architecture explicite qui gère la capture, la persistance, la récupération et l’actualisation des souvenirs selon leur type et leur usage. Dans l’écosystème actuel, notamment avec LangChain et le SDK LangMem , ces fonctions ne reposent pas sur une simple fenêtre de contexte, mais sur des composants spécialisés de gestion de mémoire (voir ici pour plus de détail).
La stack technologique moderne
Pour construire un agent capable de se souvenir, stocker et oublier, l’écosystème s’est consolidé autour de deux piliers :
- Orchestration d’état et mémoire à court terme : LangGraph permet de gérer les états de l’agent en session, ce qui correspond à l’implémentation de la mémoire à court terme (Working Memory). Il capture l’historique des interactions en cours, permet de revenir sur des états précédents ou de corriger des informations, et facilite le raisonnement en temps réel. Pour la mémoire partagée entre plusieurs agents spécialisés, CrewAI est privilégié.
- Le stockage vectoriel : des solutions comme Pinecone, Milvus ou Chroma gèrent désormais des index hybrides, combinant recherche sémantique (vecteurs) et recherche textuelle classique (BM25) pour une précision maximale. Ceci peut être une façon d’implémenter une mémoire à long terme.
Points clés à retenir
- La mémoire peut être organisée en plusieurs niveaux : comprendre et exploiter les différents niveaux (court terme, épisodique, sémantique, procédurale) permet d’améliorer la pertinence et la cohérence des interactions avec l’agent.
- Adapter la mémoire à l’usage : selon le type d’application, certaines mémoires prennent le pas sur d’autres ; par exemple, la mémoire procédurale pour des actions automatisées répétitives, ou la mémoire épisodique pour des assistants personnalisés.
- Une architecture hybride est essentielle : un agent performant ne repose pas uniquement sur la récupération de connaissances via RAG. Il doit combiner :
- Mémoire sémantique (RAG) : récupère les faits et connaissances pertinents.
- Mémoire procédurale / workflows : conserve les stratégies et séquences d’action réutilisables.
- Mémoire longue structurée : assure continuité et cohérence entre les sessions.