Dans cet article, nous montrons qu’un modèle de speculative decoding (Eagle3) présente un écart significatif d’acceptance rate entre l’anglais et le français, et qu’un fine-tuning léger et ciblé permet de réduire cet écart et d’améliorer significativement l’accélération obtenue via le speculative decoding.
L’expérience est reproductible (Colab public disponible).
Contexte : speculative decoding et acceptance rate
Le speculative decoding repose sur un modèle “draft” (speculator) qui propose plusieurs tokens en avance, et sur un modèle principal qui accepte ou rejette ces propositions. (voir le précédent blog post pour plus de détails).
Une métrique clé est l’acceptance rate par position :
- Position 1 : le token immédiatement après le préfixe (prompt + tokens générés)
- Position 2 : le deuxième token spéculé
- Position 3 : le troisième token spéculé
- etc.
En pratique, un acceptance rate plus élevé se traduit directement en accélération. Plus le modèle accepte de tokens spéculés consécutifs, moins il doit effectuer de vérifications coûteuses avec le modèle principal. Cela augmente le nombre de tokens générés par seconde et réduit la latence globale. Nous détaillons ce lien plus formellement dans un précédent blog post,, mais on peut retenir ici que l’acceptance “profonde” (positions 2, 3, …) a un impact particulièrement fort sur l’accélération.
Observation initiale : un écart massif entre anglais et français
Pour isoler l’effet langue, nous avons utilisé le benchmark MT-Bench French sur Hugging Face, qui contient des prompts identiques en anglais et en français. le benchmark contient 80 conversations, soit environ 160 prompts (2 tours par conversation), ce qui permet d’obtenir une estimation relativement stable des acceptance rates.
Baseline — Acceptance per position (k=3)
EN
[0.768 0.557 0.376]FR
[0.586 0.349 0.188]L’écart est particulièrement marqué en profondeur : en position 3, on passe de 0.376 → 0.188 soit 2× moins d’acceptation, et l’acceptation en position 2 pour le français (0.349) est plus basse que l’acceptation en position 3 (0.376) pour l’anglais.
Cela signifie concrètement qu’il y a moins d’accélération pour les prompts français. A tâche équivalente, il y a donc un écart dans l’acceptance rate qui s’explique principalement par la langue.
Interprétation de l’écart des acceptance rates du speculator
Cet écart n’est pas étonnant puisque les modèles Eagle3 ont été entraînés seulement sur de l’anglais (voir la fiche du modèle sur Hugging face). Il est même assez surprenant que les performances sur le français soient aussi hautes, preuve qu’il y a eu tout de même un phénomène de transfer learning de l’anglais vers le français.
Expérience : fine-tuning ciblé sur 5k samples français
Pour réduire l’écart des acceptance rates, nous avons appliqué un fine-tuning minimal du speculator Eagle3 sur un corpus français.
- ~5 000 exemples issus de Hugging Face (dataset french_instruct)
- Réponses générées par le modèle de référence Llama 3.1 8B Instruct
- Entraînement court : ~40 minutes sur une A100 40GB
L’objectif est de réaligner sa distribution sur le français.
En pratique, cela correspond à un fine-tuning très léger (peu de données, peu d’epochs, aucune modification d’architecture). Tous les détails techniques (hyper-paramètres, scheduler, etc.) sont disponibles en annexe.
Résultats après fine-tuning
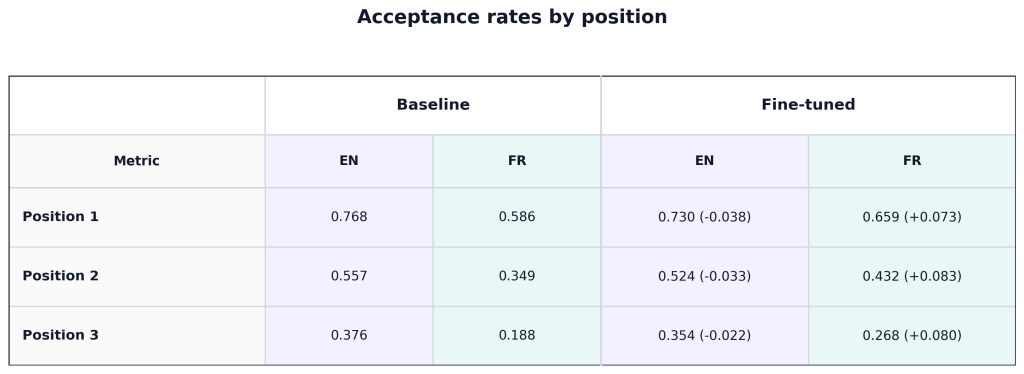
Gain sur le français:
- +0.073
- +0.083
- +0.08
Il y a une amélioration homogène sur toutes les positions, et in fine, potentiellement un gain d’accélération d’environ 30% sur le français. Cette estimation est dérivée de l’augmentation de la longueur d’acceptation attendue (mean acceptance length), qui est fortement corrélée à l’accélération observé en pratique.
L’anglais reste stable. On n’observe pas d’effondrement sur l’anglais mais une légère baisse marginale des performances, alors même qu’il n’y avait aucun contenu anglais dans les données d’entraînement du fine-tuning.
Analyse : ce que cela révèle et les implications pour la production
Cette expérience suggère plusieurs points structurants :
1. Le speculative decoding est très dépendant de la langue.
Les prompts non-anglais sont fortement désavantagés.
2. Un fine-tuning léger et relativement simple à mettre en place suffit à réduire l’écart d’acceptance rate.
Voici quelques ordres de grandeur :
- Quelques milliers à quelques dizaines de milliers d’exemples suffisent souvent pour adapter le speculator à une langue. Cela ne nécessite ni dataset massif ni full retrain : on vise un fine-tuning léger d’adaptation, pas une ré-optimisation complète du modèle. Enfin, il n’y a pas besoin de données annotées à la main : avec des prompts de bonne qualité (le mieux est d’avoir ceux utilisés en production), on génère automatiquement les réponses cibles via le modèle verifier (celui utilisé), puis on constitue le dataset d’entraînement à partir de ces paires prompt/réponse.
- Durée d’entraînement : sur un modèle de l’ordre de 1–2B de paramètres, un fine-tuning léger se fait rapidement, typiquement autour d’1 heure, car il ne nécessite que 2–3 epochs sur un volume d’exemples limité.
3. Fine-tuning continu faisable.
Le fine-tuning continu consiste à mettre à jour régulièrement les poids du modèle au fil des nouvelles données (par exemple chaque nuit) afin de rester aligné avec la distribution réelle en production. Là où un LLM généraliste ne peut pas être fine-tuné aussi fréquemment sans risque de dégrader des compétences acquises (d’où des cycles de post-training rares et très contrôlés, avec des données annotées de haute qualité), notre cas relève d’un problème d’adaptation/prédiction : on peut donc itérer plus souvent sur des données non annotées manuellement. En pratique, vLLM permet désormais d’extraire les hidden states directement à l’inférence, en ligne, ce qui facilite la collecte de données en production et l’alimentation d’un pipeline de fine-tuning continu avec un cycle court (Pour en savoir plus, voici un article sur le sujet).
4. Pas de trade-off majeur inter langue.
On peut corriger un biais sans détériorer la langue dominante.
Cela ouvre plusieurs pistes :
- Speculators spécialisés par langue et/ou par domaine (legal, code, finance)
- Routing intelligent selon workload
- apprentissage continu à partir des logs de la production pour maximiser les performances
Dans des environnements multilingues, un modèle draft fine-tuned peut réduire significativement la variance de performance entre les langues.
Démonstration vidéo
Appendix
Autres langues, point d’attention
Attention tout de même, le fine-tuning a fonctionné pour le français, mais les résultats peuvent être complètement différents selon la langue, notamment pour des langues dans d’autres alphabets. Durant la phase de training (from scratch) des modèles eagle3, le vocabulaire peut être réduit de ~130k à 32k en fonction des tokens les plus fréquents dans les données d’entraînements afin de réduire considérablement la taille du modèle eagle3 (ce fut exactement le cas dans notre exemple et vous pouvez le vérifier dans le config.json du modèle sur hugging face: ‘ “draft_vocab_size”: 32000‘ .
Nous soupçonnons que cette réduction du vocabulaire peut rendre le fine-tuning inefficace sur des langues avec un autre alphabet que l’alphabet latin. Dans ces cas, il faudra considérer un ré-entrainement from scratch mais avec cette fois un vocabulaire de tokens sur-mesure (qui se forme automatiquement avec la librairie speculators).
Reproductibilité
Notebook Colab disponible (A100 40GB utilisé): (Colab public disponible)
Logs inclus.
Expériences
Nous avons fine-tuné Eagle3 sur :
- Dataset :
angeluriot/french_instruct - ~5000 échantillons
- Réponses générées via le modèle verifier :
meta-llama/Llama-3.1-8B-Instruct - 2 epochs
- lr 6e-5
- seq_len 8192
- 1 layer draft
- ttt-steps 3 (la loss se calcule sur une spéculation allant jusqu’à 3)
- ttt-step-loss-decay 0.95 (décroissance de la loss pour le token en bout de spéculation pour diminuer leur importance)
- scheduler-warmup-steps 120 (IMPORTANT, en fine-tuning, il est essentiel d’avoir un warmup pour que le learning rate monte progressivement afin de ne pas “casser” le modèle au début)
- scheduler cosine
Training time :
- GPU : A100 40GB
- Durée : ~40 minutes
- Peak VRAM : 30 GB
Nous avons également expérimenté avec un volume plus faible (~2 000 exemples), mais les gains observés étaient moins marqués.
De nombreux axes restent à explorer, notamment: l’impact du nombre d’exemples (scaling du fine-tuning), l’ajout de données multilingues (ex : mélange FR/EN) et l’ajustement des hyperparamètres (epochs, learning rate, scheduler).