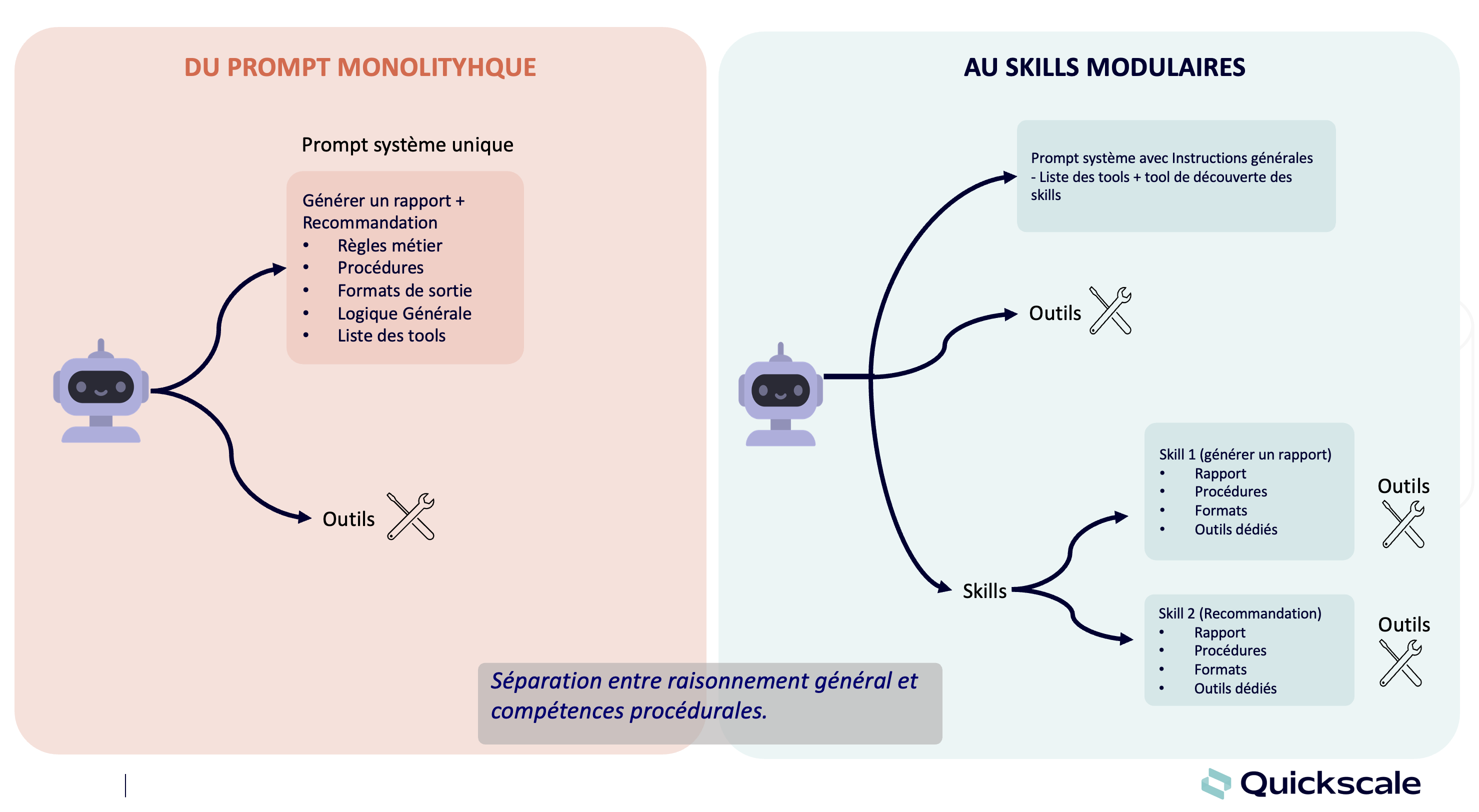
Avant même de concevoir une architecture agentique ou une pipeline RAG complète, un enjeu clé se pose : comment transformer efficacement un document brut (PDF, rapport, présentation) en données compréhensibles par un LLM ? L’ingestion des données pour une solution d’IA générative est un véritable défi. Texte, tableaux, sections, sous-sections… tout doit être extrait, classé et structuré avec précision. C’est précisément là que le modèle de parsing Granite-Docling se démarque.
Développé par IBM, Granite-Docling est un modèle open source pensé pour l’end-to-end document understanding. Il s’appuie sur une architecture Vision-Language optimisée (Granite 165M + SigLIP2) et un format propriétaire de représentation des documents, les DocTags : une alternative plus stable et plus exploitable que les sorties HTML souvent produites par les parsers LLM classiques.
Ce blogpost présente comment utiliser Granite-Docling dans une logique pre-RAG pipeline. À travers un cas d’usage concret, on montre comment convertir un PDF en DocTags structurés, puis comment séparer le texte et les tableaux pour alimenter, d’un côté, un moteur d’embedding textuel, et de l’autre, un outil de lecture CSV pour les données tabulaires.
Les tests de performance démontrent une extraction rapide et précise, avec un coût quasi nul (open source et exécutable localement sur Mac Silicon). Certaines limites de Granite-Docling existent, mais le modèle reste un candidat idéal pour le parsing documentaire.
L’importance de l’ingestion des données
Les solutions d’intelligence artificielle générative (qu’il s’agisse des approches RAG ou des architectures agentiques) reposent sur la capacité à exploiter efficacement des données non structurées : textes libres, documents PDF, images, rapports, présentations, etc. Ces données, souvent hétérogènes et désordonnées, doivent être rendues compréhensibles pour les LLM, éléments centraux de ces systèmes. L’enjeu consiste donc à transformer ces informations brutes en formats semi-structurés, voire structurés, afin d’améliorer la qualité du retrieval, la pertinence du in-context learning et la fiabilité de l’usage d’outils par les agents.

Pour atteindre cet objectif, plusieurs familles de modèles existent : les modèles de parsing documentaires comme Docling (basé sur l’OCR), les modèles layout-aware comme LayoutLM (transformer intégrant la structure du document), ou encore les modèles vision-language de nouvelle génération, tels que Granite-Docling, capables d’interpréter un document dans toute sa complexité visuelle et textuelle.
Dans un pipeline RAG classique, l’ingestion des documents repose souvent sur une approche simpliste : le PDF est découpé page par page, ou en chunks d’une taille fixe (en nombre de tokens). Cette méthode, bien que pratique, fait perdre une grande partie de la richesse structurelle d’un document PDF. Les sections sont mélangées, les titres sont considérés comme du texte ordinaire, les tableaux se transforment en lignes déstructurées, et les formules mathématiques sont rarement comprises. En d’autres termes, la hiérarchie et la mise en page – pourtant essentielles à la compréhension du contenu – disparaissent dès la première étape du pipeline.
C’est ici que Granite-Docling intervient.
De Docling à Granite-Docling
En août 2024, IBM dévoile Docling, un modèle convertissant des PDFs en JSON ou markdown. Docling réalise une suite d’actions sur chacune des pages du PDF :
- extraction du texte, avec si besoin de l’OCR
- analyse de layout
- conversion des tables à partir d’un modèle TableFormer
En septembre 2025, une nouvelle version de Docling est rendu accessible par IBM, Granite-Docling.
Granite-Docling est un modèle vision-language (VLM) open-source de 258 millions de paramètres conçu pour la conversion de documents de bout en bout (PDF, rapports, présentations) en données exploitables par les machines. Contrairement à la version précédente de la bibliothèque Docling, qui reposait sur une chaîne d’outils (OCR + layout-parser + LLM) et produisait des sorties HTML/Markdown assez génériques, Granite-Docling intègre tout en un seul passage : vision + texte + structure.
Les améliorations sont substantielles : l’encodeur visuel passe de SigLIP à SigLIP2, qui permet une meilleure localisation/spacialisation des éléments visuels (tableaux, diagrammes, etc.) et le langage de base évolue vers l’architecture Granite 165M, un modèle de language plus complet (et plus lourd) que celui de la version précédente. Autre avancée majeure : le modèle ne se contente plus d’extraire du texte, mais préserve la mise en page, repère les tableaux, les équations, le code, et restitue la hiérarchie des éléments via un format dédié, les DocTags.
Ces évolutions simplifient considérablement l’ingestion de documents dans une pipeline RAG ou agentique : plus besoin de bricoler une succession d’étapes manuelles, Granite-Docling produit un artefact prêt à l’emploi, gérable en une seule étape, qui facilite l’indexation, l’embedding texte, la lecture tabulaire. En clair : un gain de temps, de ressources, et de fiabilité par rapport à la version précédente — idéal pour des solutions d’IA générative opérationnelles.
Comment les DocTags facilitent-ils le parsing des documents ?
Les DocTags représentent une innovation majeure pour le parsing de documents PDF et l’ingestion par des LLM. Inspiré de XML, ce format personnalisé permet de capturer à la fois le contenu textuel et la structure visuelle des documents grâce à des balises spéciales, directement compréhensibles par le tokenizer des modèles. Chaque élément peut contenir des coordonnées de position sous forme de bounding box (<loc_x1><loc_y1><loc_x2><loc_y2>), permettant au modèle de situer précisément paragraphes, tableaux, sections et sous-sections sur la page. L’objectif est de fine-tuner les LLM sur ce format, pour qu’ils comprennent intuitivement l’organisation d’un document, tout en conservant la hiérarchie et la disposition visuelle. En pratique, les DocTags simplifient la conversion de PDFs en données semi-structurées exploitables : plutôt que de gérer un texte plat ou un HTML approximatif, le modèle dispose d’une représentation fidèle et standardisée, optimisée pour la génération, l’indexation et l’analyse automatisée.
Les différents éléments détectés par les DocTags sont listés dans le tableau suivant :

Comment s’en servir pour parser un PDF
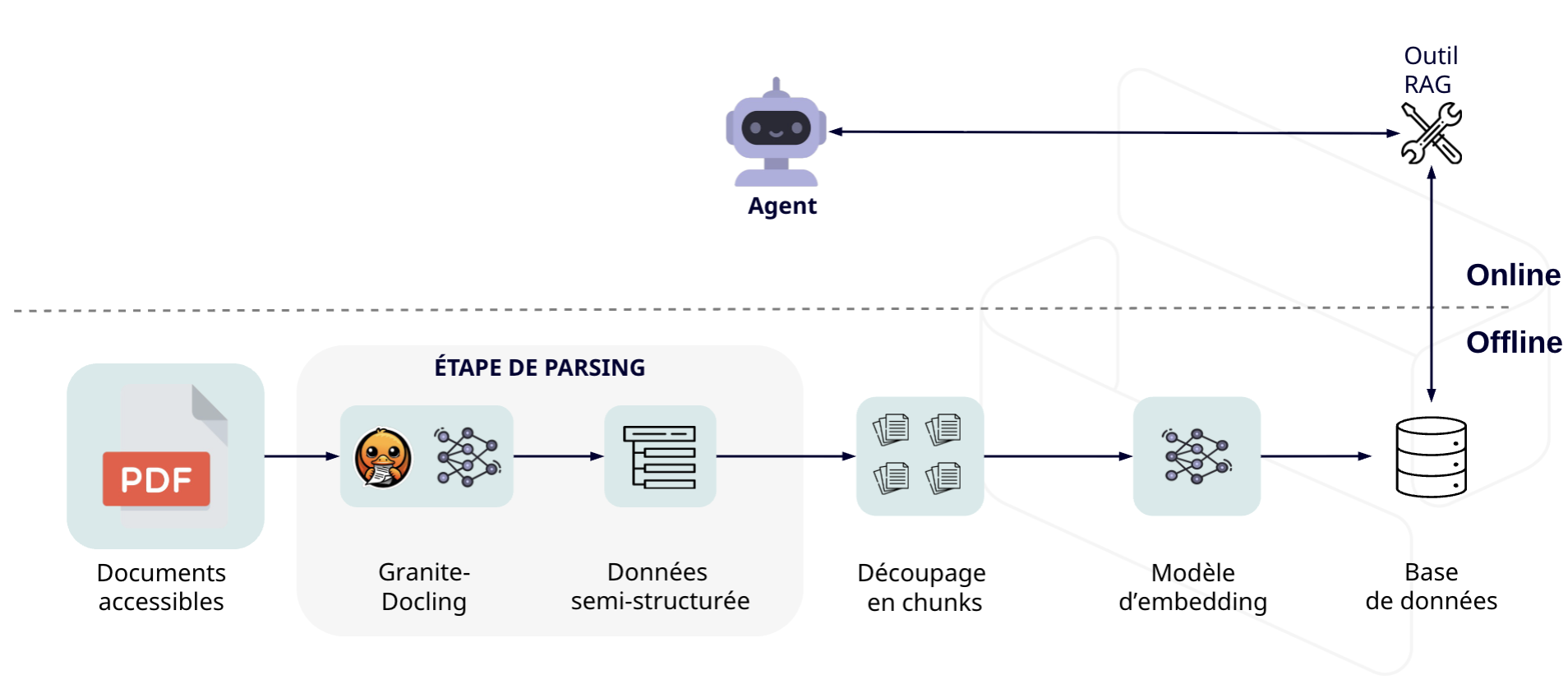
En ajoutant une étape de parsing en amont de l’indexation, on préserve la structure du document avant même de le transformer en données exploitables par un LLM. La méthode est simple :
- En entrée, un document PDF brut.
- Le modèle Granite-Docling analyse le fichier et produit une sortie au format DocTags, une représentation structurée du document (texte, titres, tableaux, sections, images, etc.), accompagnée d’une version HTML complète.
- Chaque élément identifié (qu’il s’agisse d’un paragraphe, d’un titre ou d’une table) est ensuite stocké avec ses métadonnées : type de DocTag, position, section, ou hiérarchie dans le document.
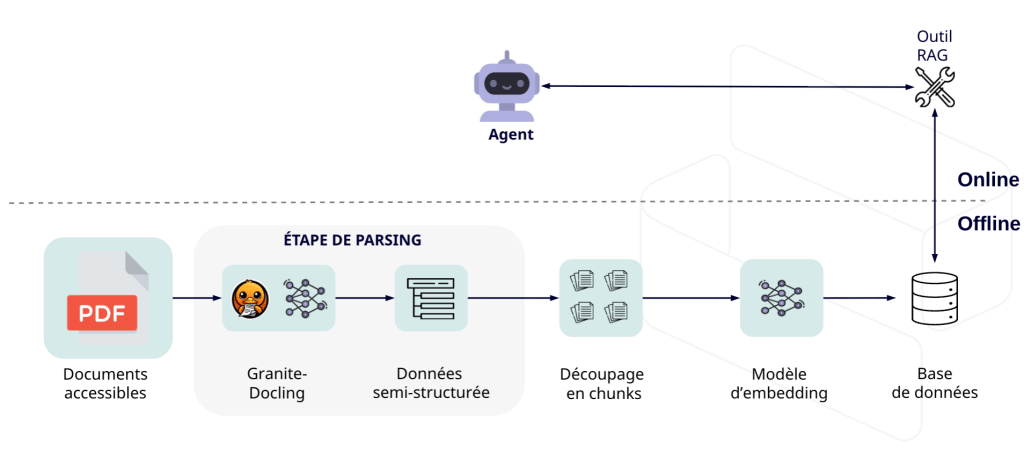
Cette étape de parsing change profondément la logique de l’ingestion : les chunks ne sont plus de simples fragments de texte, mais des unités sémantiques cohérentes, enrichies de contexte structurel. Dans une base vectorielle, ces métadonnées deviennent de puissants filtres pour la recherche. Un agent peut par exemple interroger uniquement les titres pour reconstituer une table des matières, ou chercher à l’intérieur des tables au format HTML, désormais correctement extraites et lisibles.
En intégrant Granite-Docling avant l’indexation, la pipeline RAG gagne en précision, cohérence et interprétabilité : le modèle ne “voit” plus un simple flux de texte, mais un document dans toute sa logique interne. Une évolution essentielle pour passer d’un RAG textuel à une compréhension documentaire véritablement structurée.
Granite-Docling : des performances comparables à GPT-4o-mini pour le parsing documentaire
Pour tester la robustesse du parsing, nous avons soumis 15 pages de documents PDF variés à Docling Granite et à GPT-4o-mini (via l’API Openai). Les documents incluaient des tableaux complexes, des images intégrées et des informations réparties selon le layout de la page. Dans le cas de GPT-4o-mini, le modèle a été guidé par un prompt demandant d’extraire et de convertir le contenu en HTML exploitable.
Les résultats sont sans ambiguïté : Granite-Docling atteint des performances équivalentes à GPT-4o-mini, tout en offrant un temps d’exécution réduit et un coût nul. Le coût apparent du parsing avec GPT-4o-mini peut sembler faible, mais il faut le replacer dans le contexte : seules 15 pages ont été traitées, et cela ne couvre que l’étape d’ingestion. Les autres coûts associés au RAG (embeddings, génération de réponses, supervision) restent à prendre en compte.
Cette expérimentation montre qu’il est désormais possible de mettre en place une pipeline de parsing documentaire performante et économique, capable de transformer vos PDFs en données structurées sans sacrifier la qualité ni la rapidité.

Les exemples suivants illustrent concrètement le rendu HTML produit par Granite-Docling et GPT-4o-mini à partir d’une page PDF.
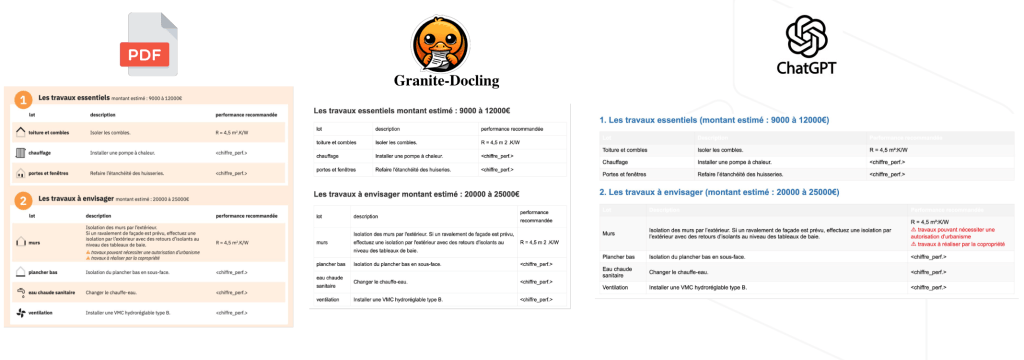
Bien que la plupart des données tabulaires soit correctement extraites, certains tableaux complexes restent mal restitués par les deux modèles.
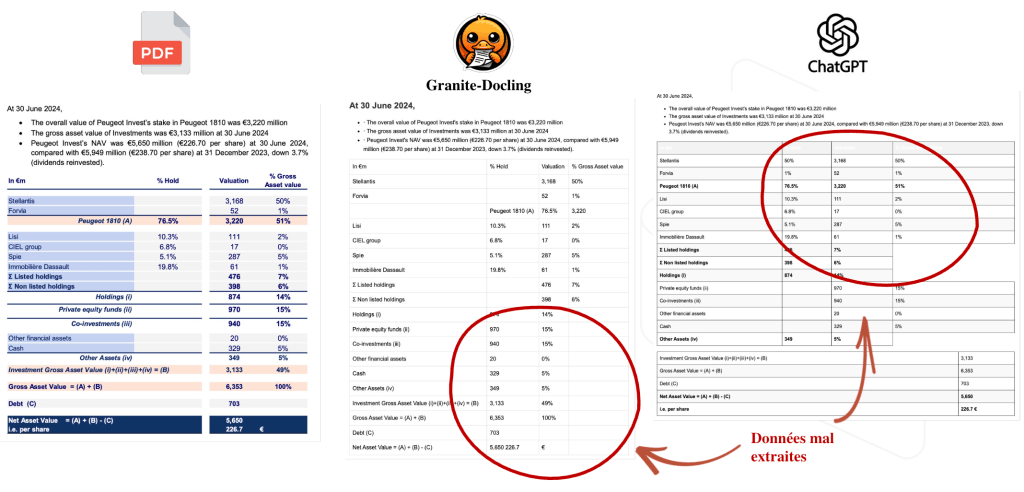
En résumé, si certaines limites persistent sur l’extraction de tables complexes, le rapport performance / accessibilité fait de Granite-Docling un excellent candidat pour les pipelines de parsing documentaires rapides et légères.
Un modèle open-source performant pour une tache d’ingestion des données cruciale
Granite-Docling dévoile des performances de parsing similaire à celles des modèles propriétaires, lourds et coûteux. Son rôle de conversion des documents, les rendant interprétables par les LLM est central dans toutes les solutions basées sur des données non-structurées : RAG, agents IA connectés au web ou générateurs de résumés de documents.
Le volume de documents à traiter par ces systèmes d’IA étant en pleine expansion, faciliter l’ingestion des documents est un enjeu crucial pour rendre ces systèmes performants. Rapide, léger et open-source, Granite-Docling s’impose comme une solution de premier plan.
En fonction de la complexité des documents à parser, une solution sur-mesure peut se montrer intéressante. Dans le cas de documents très spécifiques, ou ayant un layout récurrent , le sur-mesure peut s’avérer plus rapide et plus efficace. Il faut garder en tête que Granite-Docling est basé sur des modèles entraînés sur des grandes quantités de données, qui restent généralistes.