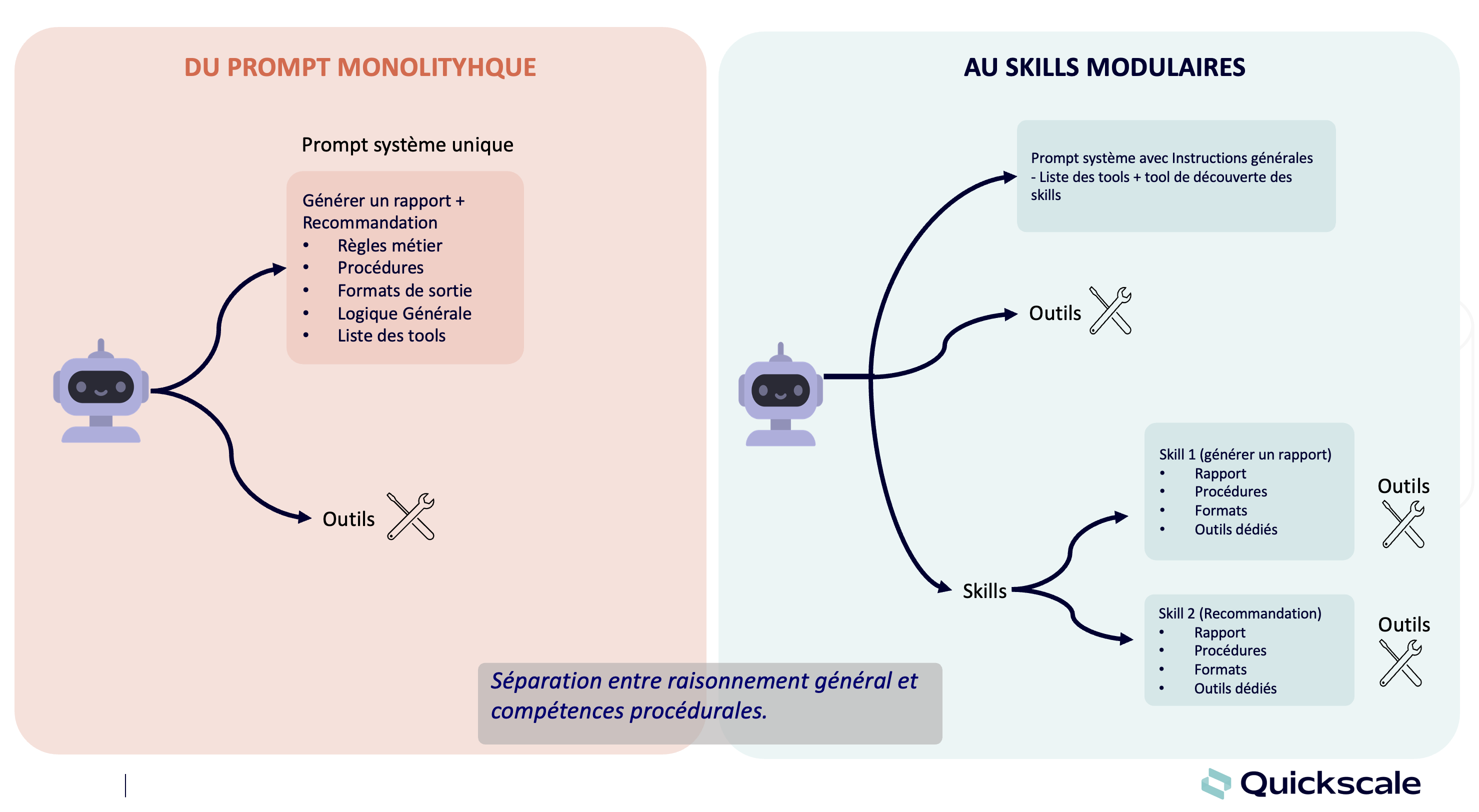
Introduction
Ouvrir Slack, poser une question à ChatGPT, suivre un cours en visioconférence… toutes ces expériences ont un point commun : elles donnent l’impression que la machine répond en temps réel, sans attendre la fin d’un calcul complexe. Cette fluidité est devenue la norme : l’utilisateur moderne n’accepte plus les délais, il s’attend à une conversation instantanée et naturelle, qu’il s’agisse d’un collègue ou d’un copilote IA.
Pourtant, derrière cette simplicité apparente, la plupart des infrastructures applicatives ne sont pas conçues pour le temps réel. Les API REST classiques, pensées pour des requêtes ponctuelles, montrent vite leurs limites dès qu’il s’agit de maintenir une connexion ouverte, d’envoyer des mises à jour progressives ou de diffuser des messages à plusieurs clients simultanément. Résultat : frustration utilisateur, coûts réseau qui explosent, et souvent des architectures bricolées avec du polling ou du long-polling inefficace.
C’est précisément là qu’interviennent les WebSockets et le streaming en temps réel. Ils offrent un canal de communication permanent entre le serveur et le client, permettant d’envoyer et de recevoir des informations de manière continue et quasi-instantanée. C’est la brique technique qui rend possible un chat moderne, un tableau de bord qui se met à jour sous vos yeux, ou encore une réponse d’agent IA diffusée token par token.
Dans ce billet, nous allons voir comment fonctionnent les WebSockets, pourquoi ils sont devenus essentiels pour le streaming temps réel dans l’ère des agents IA interactifs, et surtout comment ils transforment l’expérience utilisateur et le ROI des applications interactives.
REST vs WebSocket : comprendre le changement de paradigme
Avec une API REST, chaque échange suit le cycle : ouverture de la connexion → envoi de la requête → attente de la réponse complète → fermeture. C’est robuste… mais inadapté dès qu’il faut échanger rapidement et souvent.
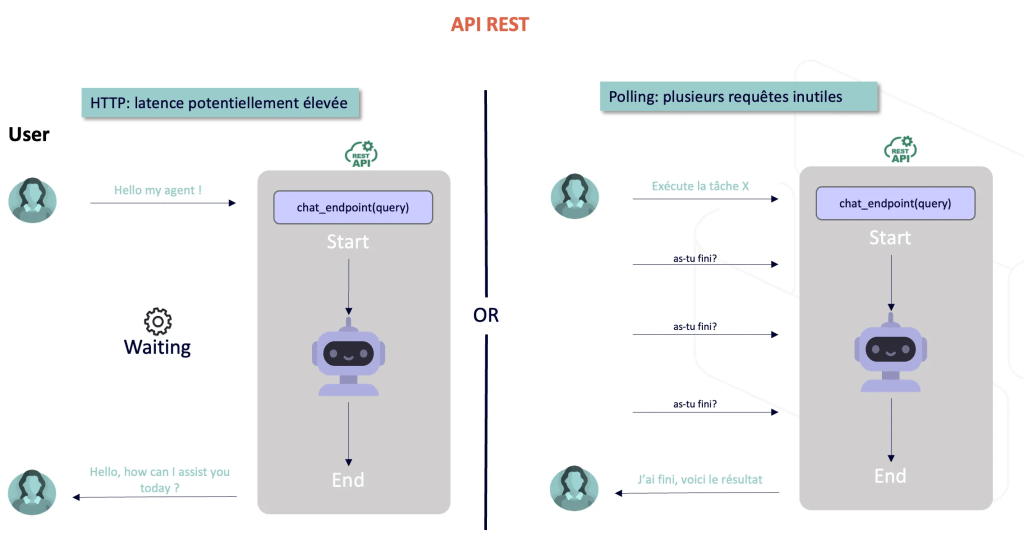
Les développeurs ont longtemps contourné cette limite avec des techniques comme le polling (demander régulièrement au serveur : “as-tu du nouveau ?”) ou le long-polling (maintenir une requête ouverte jusqu’à ce qu’une réponse arrive). Ces solutions bricolées fonctionnent, mais elles créent de la latence perceptible et surtout du gaspillage de ressources : le serveur et le client passent leur temps à échanger pour “rien”.
Le protocole WebSocket change radicalement la donne. Une fois la connexion initiale établie (en HTTP classique), le client et le serveur ouvrent un canal bidirectionnel permanent. Désormais, c’est le serveur qui envoie les informations dès qu’elles sont prêtes, et le client qui peut répondre immédiatement, sans négociation supplémentaire du type régulièrement demander “as-tu du nouveau ?”.

Dans un chat temps réel, cela veut dire que le message envoyé par Alice apparaît instantanément chez Bob, sans attendre un rafraîchissement. Dans un copilote IA, cela signifie que la réponse d’un modèle de langage peut s’afficher au fil de l’eau, mot par mot ou token par token, exactement comme si l’agent “écrivait” devant vous. La différence peut paraître subtile, mais l’effet utilisateur est immense : on passe d’un système qui “répond” à un système qui interagit.
Expérience utilisateur : immédiateté, immersion et efficacité réseau
Avec une API REST classique, chaque message implique une nouvelle requête : ouverture de connexion, envoi, attente, fermeture.
Résultat : à chaque interaction, le client et le serveur rejouent tout le cycle réseau — un gaspillage invisible, mais massif à l’échelle d’une application active.
Avec WebSocket, la logique change radicalement : une seule connexion persistante transporte un flux continu de données dans les deux sens.
Plus besoin de recréer le canal à chaque échange. Chaque token généré par le modèle, chaque réaction du serveur est envoyé instantanément, dès qu’il est disponible.
L’utilisateur ne voit plus une réponse “figée” apparaître d’un bloc. Il voit la réponse se construire, mot par mot — un effet vivant qui réduit la latence perçue, tout en diminuant drastiquement la charge réseau.
C’est un double gain :
- du côté utilisateur, immédiateté et immersion ;
- du côté serveur, moins de connexions ouvertes, moins de bande passante consommée, plus de scalabilité.
En somme, WebSocket transforme le pipeline d’un système d’agents en un organisme réactif et frugal, où chaque acteur (modèle, backend, client) parle en flux plutôt qu’en blocs.
Cas minimal d’un chat en streaming
Côté serveur (FastAPI + OpenAI)
Voici un petit serveur WebSocket en Python avec FastAPI qui interroge OpenAI en mode streaming :
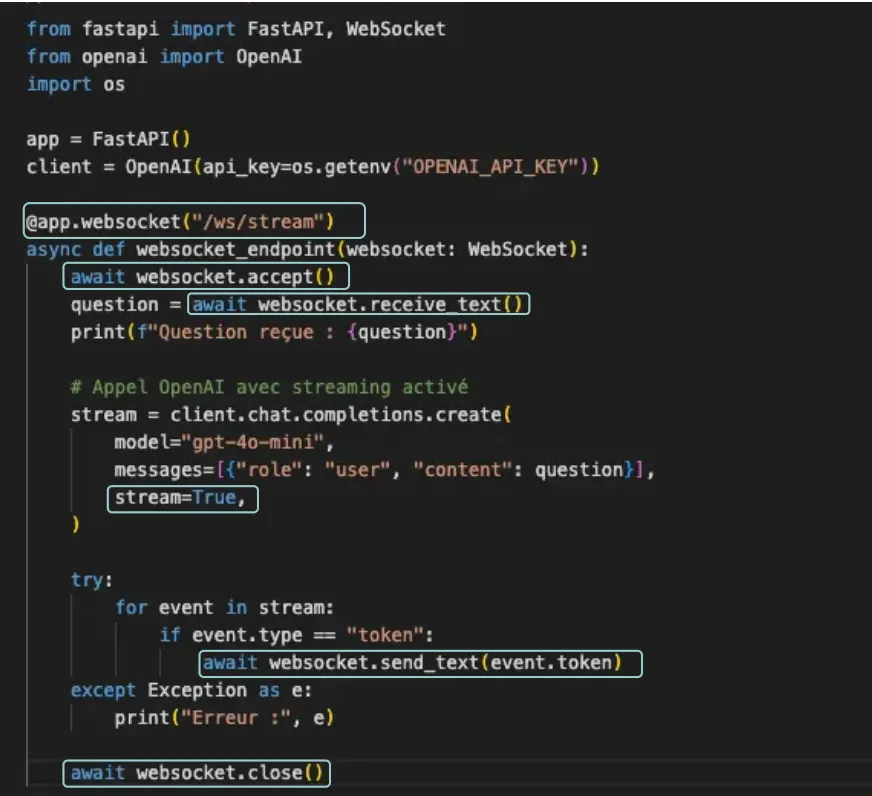
Décryptons ensemble ce code. Mais avant de commencer, notez le décorateur d’un endpoint websocket qui est @app.websocket("/ws/{nom_chemin} au lieu des routes REST @app.post ou @app.get ou d’autres.
websocket.accept(): l’ouverture du canal- Lorsqu’un client tente de se connecter à l’endpoint
/ws/stream, FastAPI doit accepter la connexion. - Contrairement au HTTP classique (requête/réponse), ici on ouvre un canal permanent : le client et le serveur peuvent s’envoyer des messages autant de fois qu’ils le souhaitent, sans repasser par la couche HTTP.
- En pratique, c’est comme si on branchait un “tuyau” entre les deux.
- Lorsqu’un client tente de se connecter à l’endpoint
await websocket.receive_text(): écoute du message entrant- Le serveur se met en attente d’un message venant du client (dans notre cas, une question utilisateur).
- C’est asynchrone : le serveur n’est pas bloqué et peut continuer à gérer d’autres connexions en parallèle.
- Une fois reçu, ce message devient la requête qu’on va passer au modèle de langage.
- Appel OpenAI en
stream=True: génération progressive des tokens- Normalement, un appel OpenAI attend que la réponse complète soit prête avant de la renvoyer.
- Avec
stream=True, le serveur reçoit un flux d’événements contenant les tokens générés au fur et à mesure. - Chaque événement est traité instantanément : on n’attend pas que le modèle ait fini de produire toute sa sortie.
- C’est exactement comme regarder quelqu’un taper sur un clavier : chaque mot apparaît au fil de la frappe.
await websocket.send_text(event.token): émission immédiate vers le client- Dès qu’un token arrive du modèle, il est envoyé par le serveur au client via le WebSocket.
- Cela crée une chaîne de diffusion en temps réel :
- OpenAI → produit un token,
- Serveur → le reçoit et le transmet,
- Client → l’affiche directement.
- C’est cette immédiateté qui donne l’impression que “l’agent écrit devant vous”.
await websocket.close(): fermeture du canal
Côté client React minimal
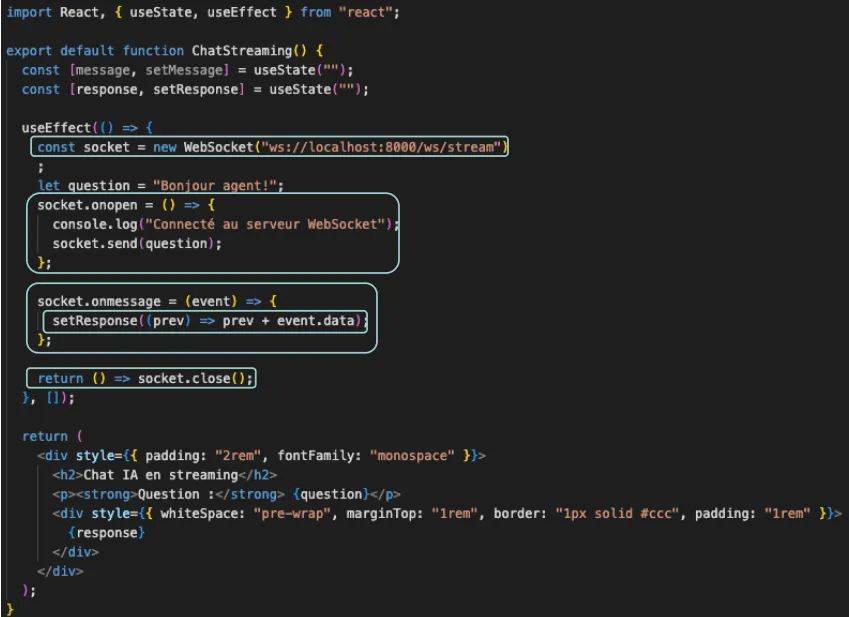
Une simple page React qui ouvre la connexion WebSocket, envoie une question et affiche la réponse token par token :
Décryptage:
new WebSocket("ws://localhost:8000/ws/stream"): ouverture du canal- Dès que la page se charge, le navigateur ouvre une connexion WebSocket avec notre serveur.
- Contrairement à
fetch(qui fait une requête unique), ici on installe une liaison permanente. - Techniquement, cela établit un tunnel bidirectionnel : le front peut envoyer des messages à tout moment, et le serveur peut pousser des données en continu.
socket.onopen = () => socket.send("Bonjour agent !"): premier message- Une fois la connexion confirmée, on peut envoyer la question de l’utilisateur.
- C’est la première interaction du client → serveur, qui déclenche tout le pipeline côté backend.
- Dans un vrai chat, c’est ce qu’on envoie au moment où l’utilisateur clique sur “Envoyer”.
socket.onmessage = (event) => { setMessage(m => m + event.data) }: réception en continu- À chaque fois que le serveur reçoit un token d’OpenAI, il le retransmet aussitôt au client.
- Le navigateur reçoit donc une succession de petits morceaux de texte (chunks), chacun contenant un mot, une syllabe ou un caractère.
- La fonction
setMessagepermet d’ajouter ce morceau au texte déjà affiché. Résultat : la réponse se construit à l’écran, en direct. - C’est un vrai streaming text UI : l’utilisateur ne voit pas un bloc figé apparaître, mais une écriture progressive.
- Gestion de l’état :
useStatecomme mémoire locale- Dans React,
const [message, setMessage] = useState("")sert de “mémoire tampon” pour stocker ce qui s’affiche. - Chaque nouveau token reçu met à jour cet état, et donc l’interface.
- C’est un mécanisme fluide et réactif : pas besoin de recharger la page ni de relancer une requête.
- Dans React,
Autres exemples en IA générative
Le pattern WebSocket + streaming s’applique bien au-delà du simple chat :
- Résumé de documents volumineux Au lieu d’attendre la synthèse finale, l’utilisateur voit la première partie du résumé défiler. Il peut déjà commencer à lire pendant que le reste est généré.
- Traduction en temps réel Les phrases traduites apparaissent dès que le modèle les produit. Idéal pour les sous-titres automatiques ou la traduction de visioconférences.
- Code assistant Lorsqu’un LLM génère du code, chaque bloc est envoyé au fur et à mesure. Le développeur peut déjà copier ou analyser les premières lignes.
- Recherche augmentée (RAG) Un pipeline multi-agents (RAG + API + LLM) peut pousser ses résultats partiels dès qu’ils sont disponibles, plutôt que d’attendre la fusion finale.
En résumé
- REST reste performant pour des requêtes ponctuelles, mais atteint vite ses limites dès qu’il faut maintenir des interactions continues.
- WebSocket établit un canal bidirectionnel persistant, permettant le streaming token par token sans réouvrir de connexion.
- Concrètement, un serveur (FastAPI + OpenAI) envoie chaque chunk de génération au fil de la réponse, pendant qu’un client React affiche le texte en direct.
- En IA générative, les usages sont multiples : chat, traduction instantanée, résumé de documents, ou copilotage de workflows complexes.
- Et l’impact utilisateur est immédiat : plus de fluidité, plus de confiance, plus d’engagement.
En somme, on ne consomme plus une réponse : on vit une interaction fluide et naturelle.
Conclusion
Dans un monde où la vitesse, la réactivité et la transparence deviennent des standards, les API REST classiques ne suffisent plus. Pour offrir un chat moderne, un copilote IA réactif ou une application collaborative temps réel, il faut adopter le paradigme du flux continu. Les WebSockets et le streaming temps réel ne sont pas qu’une innovation d’ingénieurs. Ils redéfinissent la relation entre l’utilisateur et l’application : là où hier on “consommait un service”, aujourd’hui on participe à une interaction vivante. Oui, cela demande une infrastructure solide, une gestion fine des connexions et un monitoring attentif. Mais le retour est clair : moins de latence, moins de charge réseau, plus de satisfaction utilisateur. Et à l’heure où les copilotes IA sortent des labos pour s’intégrer dans les outils métier, cette différence fait tout :celle entre une démo impressionnante… et un produit réellement adopté.