
De 512 à 10 millions de tokens : comment les LLMs ont repoussé les limites de la fenêtre du contexte
Prérequis: connaissances de base de l’architecture transformers (embeddings, token, context), connaissances de bases sur les GPU
Executive Summary
En l’espace de 7 ans, les modèles de language sont passés d’une fenêtre de contexte de 512 tokens à plus de 10 millions. Cette avancée ouvre des possibilités nouvelles pour analyser des documents entiers, des historiques de conversations ou des bases de données complètes sans aucun découpage manuel. Dans un contexte où les entreprises cherchent à automatiser l’analyse documentaire ou la compréhension de données massives, comprendre ces innovations techniques est crucial pour identifier les prochains cas d’usage à fort impact business.
De quelques paragraphes à une mini-bibliothèque
L’allongement de la fenêtre de contexte bouleverse les usages des LLMs : analyse documentaire sans chunking, résumés de milliers de pages, ingestion de bases de données entières. Comprendre comment on est passé de 512 à 10 millions de tokens, c’est anticiper les futurs cas d’usage qui vont transformer les systèmes LLMs tels que les RAG ou les agents.
En 2018, BERT se contentait de 512 tokens. Sept ans plus tard, Llama 4 Scout passe la barre des 10 millions : de quoi contenir l’intégralité d’un dépôt Git ou le texte complet de Guerre et Paix de Tolstoï… treize fois.
Cette multiplication par un facteur 20 000 du contexte disponible ouvre de perspectives nouvelles pour les LLM : lecture et traitement de documents entiers sans découpage, analyse de longs historiques de conversation, modélisation de codes sources complets.
Mais attention, comme nous le verrons, tout n’est pas si simple et il subsiste encore des frictions pour tirer pleinement parti de ces fenêtres de contexte gigantesque.
Pourquoi étions-nous bloqués à 512 tokens ?
Avant de comprendre comment cette limite a été repoussée, il est essentiel de cerner pourquoi elle a longtemps semblé infranchissable.
self-attention
L’une des forces des Transformers est le self-attention, qui permet à chaque token de se connecter à tous les autres pour capter des dépendances longues. Mais cette capacité a un prix : la matrice d’attention est de taille n × n, ce qui implique une complexité en O(n²) en mémoire et en calcul. Sur quelques milliers de tokens, cette charge reste supportable. Mais lorsque le contexte s’étend à plusieurs centaines de milliers, voire plusieurs millions de tokens, la matrice devient tout simplement trop grande pour la mémoire GPU, et le coût de calcul devient prohibitif.

Figure 1: Visualisation des poids d’attention dans un Transformer. Chaque mot (en pratique token) établit une connexion avec tous les autres mots. Pour une séquence de n mots, cela conduit ainsi à n connexion pour chaque mot, d’où $n^2$ connexions en tout.
Positional encoding
Autre caractéristique clé des Transformers : la notion de positional encoding. Par défaut, les Transformers sont en quelque sorte indifférents à l’ordre des tokens, car ils ne contiennent pas de mécanisme de récurrence pour comprendre la séquence (1). Pour eux, une phrase est simplement un sac de token, sans ordre.
Pour résoudre ce problème, on ajoute la représentation vectorielle de chaque token un nouveau vecteur représentant sa position dans la phrase : c’est ce qu’on appelle le positional encoding. Ces vecteurs sont souvent calculés selon des fonctions sinusoïdales, dont les motifs varient progressivement avec la position. Ainsi, le modèle peut distinguer “Le chat mange la souris” de “La souris mange le chat”.
En théorie, ces encodages sinusoïdaux peuvent s’étendre à des séquences très longues. Mais en pratique, au-delà de quelques milliers de tokens, les valeurs se répètent ou deviennent instables, ce qui empêche le modèle de capturer correctement les relations à longue distance.
Ces deux notions de self-attention et de positional encoding, qui constituent finalement aussi bien les limites que les forces des Transformers, expliquent pourquoi pendant longtemps, les LLMs restaient bloqués autour de 512 ou quelques milliers de tokens.
Pour repousser cette limite, il a donc fallu inventer de nouvelles techniques d’ingénieries et exploiter au maximum les GPU de dernière génération. Et c’est précisément grâce à ces innovations que nous sommes passés de 512 tokens… à 10 millions.
Les innovations algorithmiques et matérielles
RoPE et iRoPE : la position enfin extrapolable
Les premiers Transformers utilisaient des encodages sinusoïdaux pour indiquer la position des tokens, mais ces signaux deviennent instables sur de longues séquences. RoPE (Rotary Positional Encoding) a introduit une approche plus robuste : il encode la position via des rotations complexes (complexe dans le sens mathématiques) appliquées aux vecteurs d’entrée. Cela permet au modèle de reconnaître plus facilement les relations entre tokens même très éloignés.
iRoPE, pour interleaved Rotary Positional Embedding, utilisé dans Llama 4, va plus loin : cette technique permet de lire des textes très longs sans perdre le fil. Son principe est d’entrelacer (interleave) des couches avec RoPE et des couches sans RoPE. Les couches avec RoPE gèrent les relations précises entre tokens proches, tandis que celles sans RoPE utilisent d’autres astuces pour garder une vue globale sur le texte.
iRoPE ajuste aussi dynamiquement ses calculs pendant la lecture, pour rester efficace quelle que soit la longueur du texte. Grâce à ça, Llama 4 Scout peut traiter jusqu’à 10 millions de tokens d’un seul coup, ce qui ouvre la voie à des modèles capables de travailler sur d’énormes documents ou des conversations continues. Certains parlent même d’infinity Rope pour l’iRope, car cette technique permettrait de gérer un contexte potentiellement infini…
Les encodages sinusoïdaux utilisés dans les premiers Transformers se sont révélés clairement sous-optimaux pour les longues séquences. Les nouvelles méthodes, comme RoPE et iRoPE, ont corrigé ces limites et permettent désormais aux modèles de gérer efficacement des contextes très étendus, potentiellement sans limite.
→ Le seul véritable bottleneck aujourd’hui est en fait la self-attention quadratique.
Sparse & dilated attention
L’attention dense est puissante mais coûteuse, car chaque token “regarde” tous les autres (O(n²)). Pour alléger la charge, des modèles comme Longformer ou BigBird ont introduit des stratégies dites sparse attention ou dilated attention : chaque token ne regarde qu’une partie structurée de ses voisins ou des positions-clés.
Par exemple, un token peut se connecter :
- à ses proches voisins immédiats (fenêtre locale),
- à quelques positions globales (tokens de résumé),
- ou à intervalles réguliers (dilated).
Cela réduit la complexité à O(n) au lieu de O(n²). Mais attention : ces approches peuvent perdre en finesse lorsqu’il faut comprendre des relations entre tokens très éloignés, comme dans de longues conversations ou des contrats très imbriqués.
→ Ces techniques rendent possible l’analyse de textes longs sans exploser la mémoire GPU, même si elles restent limitées dans la pratique en termes de performance.
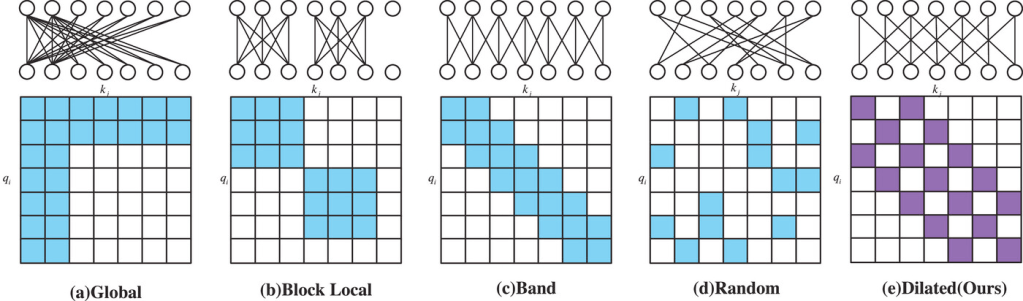
Figure 2: Différents schémas d’attention. L’approche classique du self-attention dense est l’approche global. Les approches locales, aléatoires ou dilatées réduisent le coût quadratique de l’attention dense tout en préservant une partie des dépendances longues.
FlashAttention : retour sur le dense, mais sans exploser la mémoire
Plutôt que de réduire le nombre de connexions, FlashAttention a choisi une autre voie : optimiser au maximum chaque étape du calcul à très bas niveau pour maintenir une attention dense, même sur de très longues séquences.
En quelque sorte, il s’agit d’un brute force intelligent : au lieu de simplifier le problème comme le font les méthodes “sparse”, FlashAttention a repensé l’organisation des calculs pour les rendre beaucoup plus efficaces et rapides. Résultat : on peut garder la précision de l’attention dense tout en limitant la mémoire utilisée et tout en maintenant de très bonne performance
→ Grâce à FlashAttention, les modèles peuvent gérer des séquences dix ou vingt fois plus longues sans changer de GPU, rendant possible l’analyse dense de documents entiers.
Mixture-of-Experts (MoE)
Une autre piste pour gérer de très longs contextes sans faire exploser les ressources est le Mixture-of-Experts (MoE).

Des modèles comme Llama 4 Scout ou Mixtral 8x22B MoE contiennent des dizaines voire centaines de petits sous-modèles appelés “experts.” Mais au lieu de tous les activer à chaque requête, le modèle en sélectionne seulement quelques-uns (par exemple 16 sur 128), en fonction du texte à traiter. Cela permet de réduire considérablement la charge de calcul et la mémoire consommée, tout en gardant la puissance d’un grand modèle.
→ Grâce au MoE, il devient possible de traiter des contextes de plusieurs millions de tokens sans multiplier les coûts matériels. De plus, ces modèles sont excellents en production, de façon self hosted, car ils permettent de servir plusieurs requêtes concurrentes de façon efficace, sans exploser la mémoire.
Hardware nouvelle generation
Tout cela n’aurait pas été possibles sans les progrès impressionnants du hardware ces dernières années.
Les nouvelles générations de GPUs, comme les H100 de NVIDIA ou les MI300X d’AMD, offrent bien plus de mémoire. Il y a aussi eu de grandes avancées côté réseau dans les GPU, avec des bandes passantes bien plus élevées. Cela permet de connecter plusieurs GPUs entre eux sans trop de latence ni perte liée au réseau, et de répartir efficacement la charge de travail. Il devient alors possible d’envisager l’inférence sur de très longs contextes.
Autre évolution importante : de nouvelles façons d’exécuter les calculs plus rapidement et avec moins de mémoire, grâce à des techniques comme les opérations dites “fused” (qui regroupent plusieurs calculs en un seul passage) ou l’usage de nombres plus compacts comme le FP8 (des nombres qui n’occupent qu’un octet en mémoire).
En pratique
Malgré ces avancées spectaculaires, plusieurs limites subsistent quand on veut exploiter des contextes dépassant le million de tokens.
Coûts exponentiels
Plus le contexte s’allonge, plus le coût en GPU explose. Même avec FlashAttention, traiter plusieurs millions de tokens exige plusieurs dizaines de Go de VRAM, voire l’utilisation de clusters entiers de GPU. Cela réserve ces usages aux entreprises disposant de moyens importants, ou oblige à faire des compromis sur la longueur de contexte réellement exploité.
Par exemple, ce blog post de vLLM (lien), vous décrit comment déployer un Llama4 Scout. Même sur une instance de 8 H100 GPU, qui coute environ 60$/h, et qui correspond à une VRAM (mémoire des GPU) totale de 640 GB, vous pourrez servir au maximum des requêtes de seulement 1M de token…
Latence accrue
Lire et analyser un document de plusieurs millions de tokens prend du temps. L’inférence devient plus lente, ce qui peut poser problème dans des applications nécessitant une réponse rapide (chatbots, assistants en temps réel).
Alignement et cohérence
Plus la séquence est longue, plus le risque augmente que le modèle « perde le fil » ou génère des réponses incohérentes. L’alignement du modèle sur de très longs contextes reste un défi ouvert : il n’est pas garanti que le LLM utilise efficacement tout le contexte disponible.
Absence de benchmarks publics
Il existe très peu de benchmarks standards pour évaluer la qualité des modèles au-delà du million de tokens. La plupart des publications restent internes aux laboratoires de recherche ou aux entreprises. Cela rend difficile d’évaluer objectivement les performances réelles sur des cas d’usage concrets.
En résumé, la fenêtre de contexte n’est plus un obstacle technique pur, mais elle reste encore un défi économique, pratique et de qualité des résultats.
Conclusion
Le passage de 512 tokens à plusieurs millions marque une rupture majeure dans l’histoire des LLM. Grâce à des innovations comme RoPE, FlashAttention, MoE et aux progrès matériels des GPUs, il est désormais techniquement possible de traiter des volumes de texte jadis inimaginables, ouvrant la voie à de nouveaux cas d’usage : analyse documentaire intégrale, exploration de bases de données textuelles, agents capables de raisonner sur des historiques longs.
Mais ces promesses viennent avec leur lot de défis : coûts élevés, latence accrue, difficultés d’alignement et rareté des benchmarks fiables. Dans la réalité, peu d’applications vont aujourd’hui jusqu’aux millions de tokens en production. La majorité des modèles commercialisés oscillent plutôt entre 128 000 et 1 million de tokens.
Pour les entreprises, la clé sera de comprendre quand il est réellement utile d’exploiter ces grandes fenêtres de contexte et quand des stratégies hybrides (chunking intelligent, RAG) restent plus efficaces et plus économiques.



