
Quand et pourquoi utiliser le speculative decoding
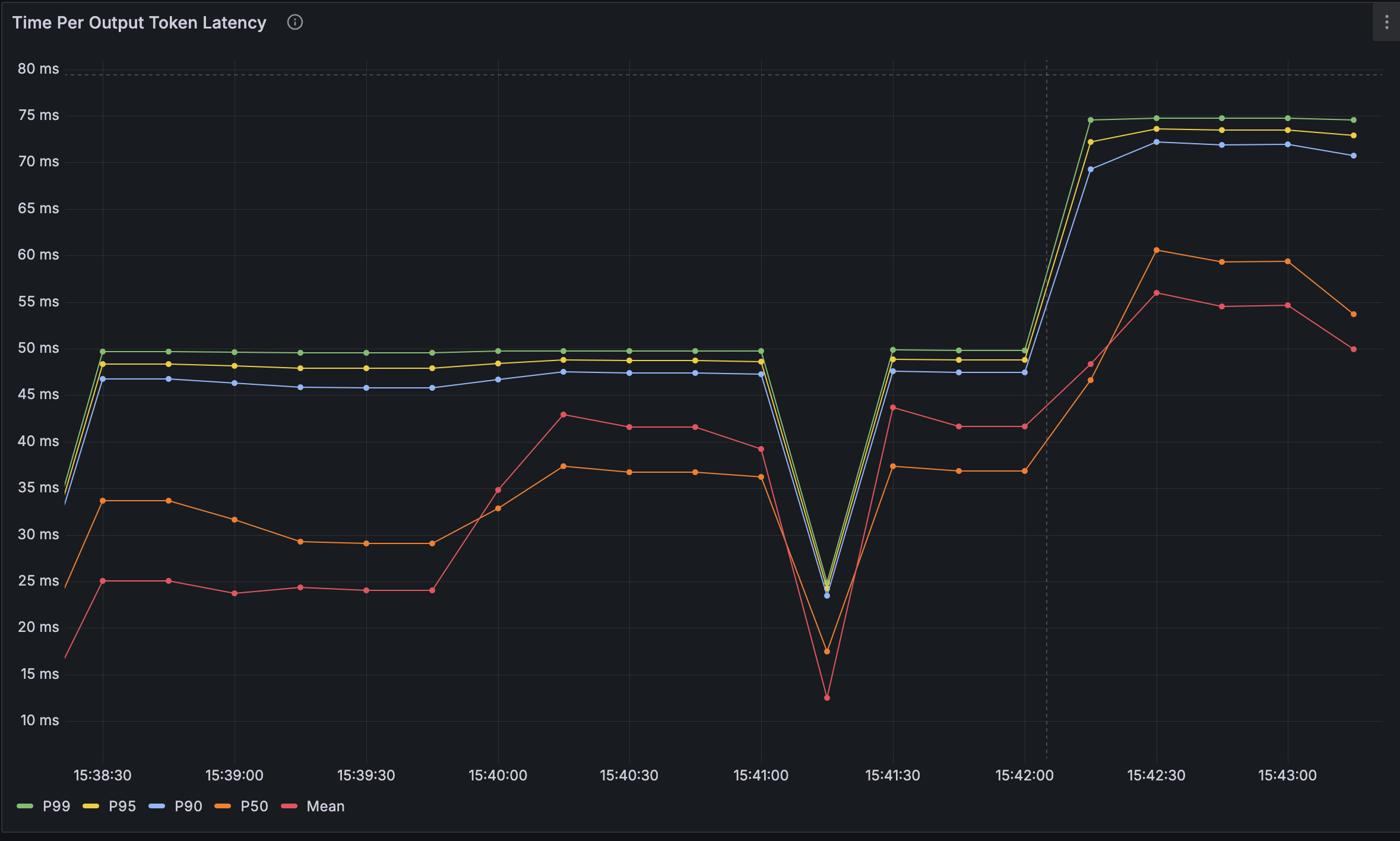
En production, chez l'un de nos clients, l’implémentation du speculative decoding avec Llama 3-70B et EAGLE-3 a permis d’observer des réductions de latence E2E allant jusqu’à ×2.5 sur des requêtes…
En production, chez l'un de nos clients, l’implémentation du speculative decoding avec Llama 3-70B et EAGLE-3 a permis d’observer des réductions de latence E2E allant jusqu’à ×2.5 sur des requêtes…
Les LLM open source comme Mistral, Llama ou GPT OSS ont ouvert des possibilités incroyables pour les développeurs et les entreprises. Cependant, passer d'un notebook de test à un déploiement…

De 512 à 10 millions de tokens : comment les LLMs ont repoussé les limites de la fenêtre du contexte Prérequis: connaissances de base de l’architecture transformers (embeddings, token, context),…
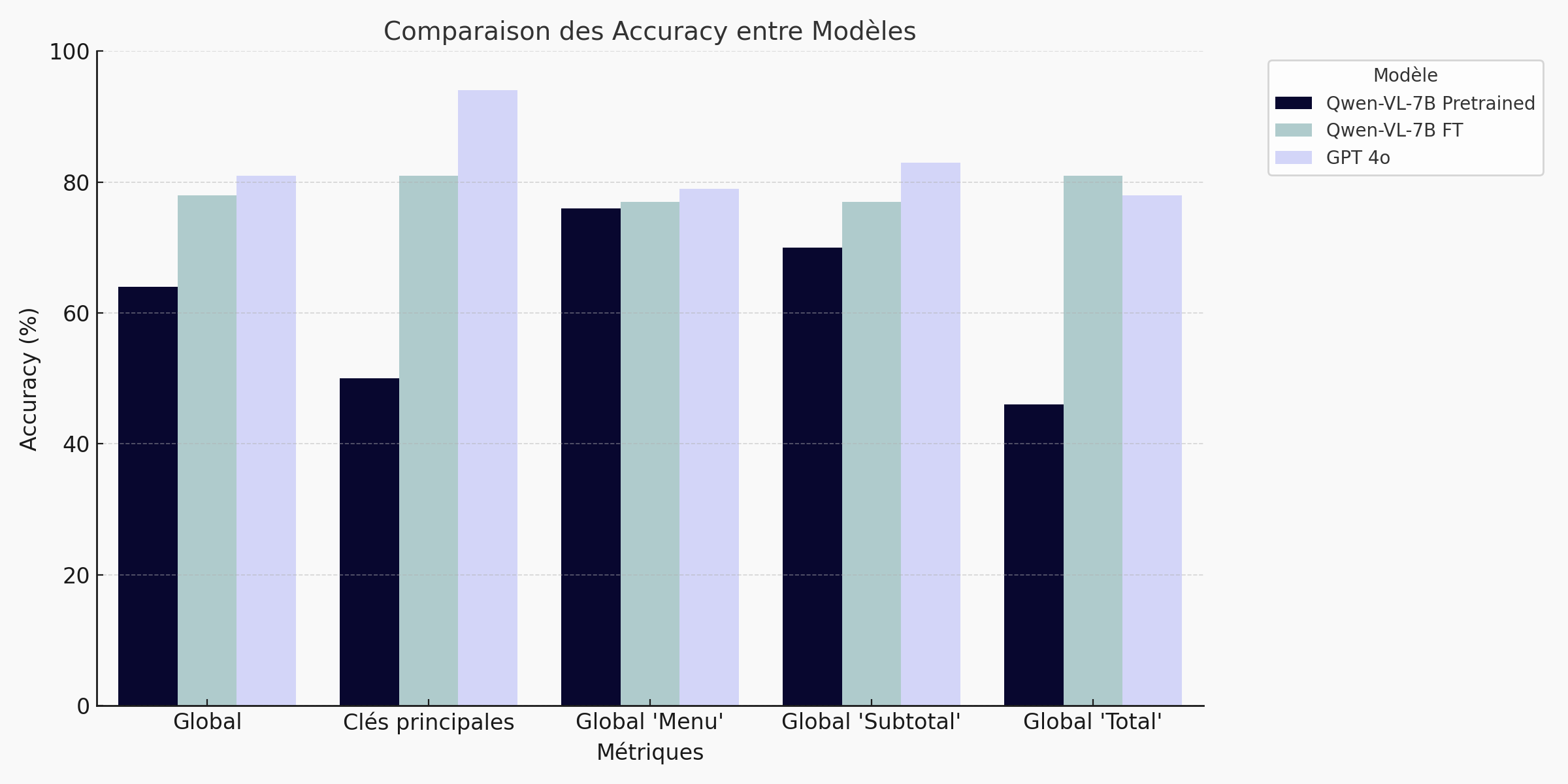
Temps de lecture estimé: 12min Les grands Visual Language Models (VLM) généralistes – GPT‑4o, Gemini 1.5 Pro… – savent déjà combiner texte et image. Pourtant, dans des contextes B2B régulés (financier, légal,…