Alors que l’industrie se concentre sur les modèles de langage géants, une transformation plus discrète redessine les possibilités du déploiement local. Les modèles open source de petite et moyenne taille franchissent un seuil critique : ils atteignent désormais des performances de niveau industriel sur de nombreux cas d’usage métier. Cette évolution change concrètement la donne. Des modèles comme Llama 3.2, Phi-4 ou Qwen 2.5 égalent ou surpassent GPT-3.5 sur des tâches spécifiques, tout en tournant sur des infrastructures standard. Pour les organisations qui manipulent des données sensibles ou cherchent à maîtriser leurs coûts d’infrastructure, c’est une opportunité stratégique qui mérite examen.
Cet article les petits modèles open-source rendent le déploiement local non seulement techniquement viable, mais stratégiquement pertinent pour les organisations qui manipulent des données sensibles.
Pourquoi les petits modèles open-source changent la donne?
Le terme « open-source » trouve ses origines dans le mouvement du logiciel libre (OSS), défini en 1998 comme un “contrat social” garantissant l’accessibilité (presque inconditionnelle) publique du code source. L’arrivée de modèles d’IA comme LLaMA, Dolly et StableLM redéfini cette notion, qui s’est aujourd’hui largement dissocié des exigences strictes des licences OSS classiques. Certains développeurs l’utilisent simplement pour signifier que leur modèle est téléchargeable, alors même que la licence peut restreindre certains cas d’usage ou modalités de distribution. Meta, par exemple, qualifie LLaMA-2 de modèle open-source, bien que sa licence interdise l’utilisation commerciale pour les développeurs dépassant 700 millions d’utilisateurs mensuels et prohibe l’usage des sorties pour entraîner d’autres grands modèles de langage.
Un modèle publié peut ensuite être exploité, pour mieux comprendre ce qui est nécéssaire à cette exploitation il faut avoir en tête qu’un développeur de modèle peut dévoiler une partie ou la totalité des quatre composants suivants: l’architecture du modèle, les poids du modèle, le code d’inférence et le code d’entrainement. A minima l’architecture et les poids d’un modèle, permettent aux utilisateurs d’exécuter le modèle pré-entraîné et de faire du fine-tuning pour l’adapter à leurs besoins spécifiques. Les ressources nécessaires pour l’inférence sont minimes (un GPU grand public comme la RTX 4090 suffit) comparées au coût d’entraînement qui requiert des milliers de GPU-heures et représente un investissement de plusieurs millions de dollars.
Si presque n’importe qui peut exploiter un modèle open-source aujourd’hui avec pour seul coup celui de l’inference, c’est aussi car les modèles de petite taille ont grandement gagné en performance, et c’est eux qui sont les plus téléchargés. Dans l’article Is Open Source the Future of AI? A Data-Driven Approach paru en mars 2025, les chercheurs du MDPI révèlent un constat contre-intuitif : les modèles de grande taille crées après janvier 2024 ne surpassent pas significativement les modèles plus compacts. Certains des modèles les plus performants, comptant moins de 20 milliards de paramètres, atteignent des résultats comparables à des modèles beaucoup plus volumineux et sophistiqués. Plusieurs innovations techniques ont rendu ces petits modèles encore plus accessibles au téléchargement et à l’exploitation: la quantization permet de réduire la précision numérique des poids du modèle (de FP16 à INT8 ou INT4), divisant l’empreinte mémoire par deux à quatre tout en préservant l’essentiel des performances, la distillation de connaissances transfère les capacités de grands modèles vers des architectures compactes, créant des “élèves” performants à partir de “professeurs” massifs. Des architectures comme Mixture-of-Experts (MoE) activent sélectivement des sous-ensembles de paramètres selon la tâche, réduisant le coût de calcul par inférence. Enfin, les techniques de fine-tuning efficace comme LoRA (Low-Rank Adaptation) ou QLoRA permettent d’adapter ces modèles pré-entraînés à des cas d’usage spécifiques en n’entraînant qu’une fraction minime des paramètres, avec des besoins en ressources dérisoires. Combinées, ces technologies ont démocratisé l’accès aux modèles de 3B à 13B de paramètres, désormais déployables sur infrastructure standard voire sur devices embarqués, ouvrant la voie à un déploiement on-premise sans dépendance aux API cloud et à une réduction drastique des coûts d’exploitation et de latence.

Les données de distribution des téléchargements sur Hugging Face confirment cette réalité : 85% des téléchargements se concentrent sur des modèles compacts ne dépassant pas 15 milliards de paramètres. C’est bien l’état l’art actuel du déploiement des LLM en conditions réelles, où l’efficacité de calcul et l’accessibilité priment sur la course à la taille. Les modèles compacts s’imposent désormais comme le standard de facto pour la majorité des applications en production, démontrant que la valeur pratique d’un modèle ne réside plus dans son nombre de paramètres, mais dans son rapport performance-coût.

Deployer ses modèles localement, une solution devenue accessible pour toutes les entreprises
Depuis 2022, le “Shadow AI” est devenu l’une des principales préoccupations des DSI et RSSI : des employés qui utilisent ChatGPT, Claude ou d’autres API propriétaires pour traiter des données sensibles, sans supervision ni traçabilité. Cartographier ces usages sauvages s’est révélé quasi impossible, garantir le respect du RGPD illusoire, et interdire purement et simplement ces outils contre-productif face à leur utilité manifeste.
Les petits modèles open-source déployables localement résolvent cette équation impossible. Avec le bon savoir-faire technique – désormais accessible grâce aux outils de fine-tuning simplifiés et aux infrastructures standardisées – toute entreprise, quelle que soit sa taille, peut déployer ses propres solutions IA internes.
Comme expliqué précédemment, les petits modèles open-source excellent dans les applications métier ciblées où la précision sectorielle prime sur la polyvalence. Un modèle de 7B paramètres, finement ajusté sur les spécificités d’un domaine (juridique, médical, financier), surpasse souvent un modèle généraliste de 70B sur des tâches spécialisées, tout en nécessitant 90% de ressources de calcul en moins.
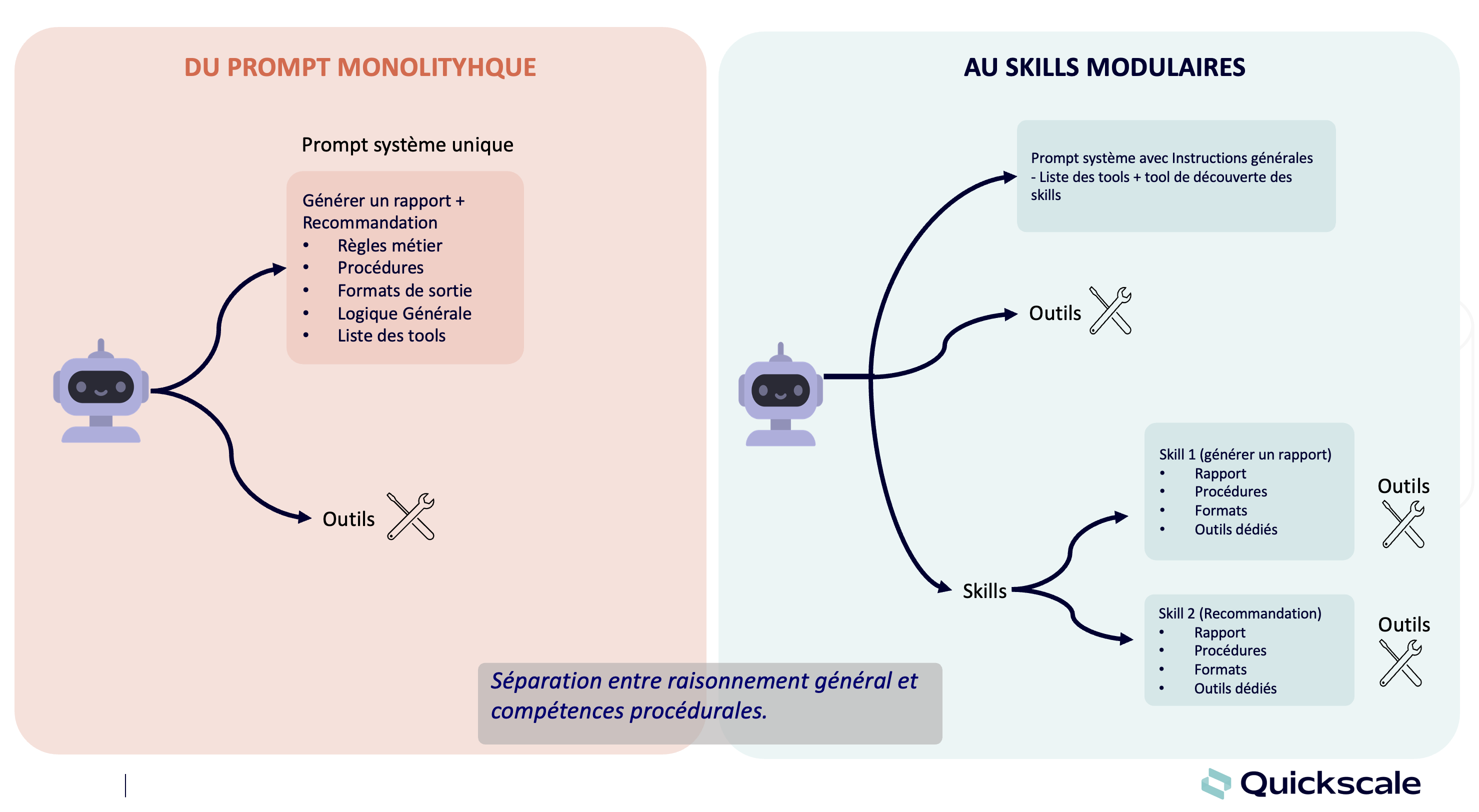
L’essor des architectures agentiques amplifie encore cet avantage. Dans un système multi-agents, chaque agent se voit confier une tâche précise et délimitée : l’un extrait les informations d’un document, l’autre les structure, un troisième les analyse selon des règles métier. Cette spécialisation des rôles permet de substituer les grands modèles généralistes par des petits modèles ultra-ciblés à chaque étape du workflow. Résultat : une orchestration d’agents légers, chacun expert dans sa micro-tâche, qui égale voire surpasse les performances d’un modèle monolithique, tout en consommant une fraction des ressources et en garantissant la traçabilité de chaque opération.
Quelques exemples d’applications à forte valeur ajoutée :
- Extraction et analyse de clauses contractuelles dans le secteur juridique
- Classification automatique de documents techniques en R&D
- Génération de rapports financiers standardisés et conformes
- Assistance à la documentation technique et maintenance industrielle
- Chatbots métier, RAG intégrant la terminologie et les processus internes
IA locale et décentralisée : Reprendre le Contrôle
Ce qu’il faut retenir, c’est la façon dont la démocratisation des petits modèles open-source redéfinit les règles du jeu. Les entreprises ne sont plus contraintes de choisir entre performance et souveraineté : des modèles compacts déployables localement atteignent désormais des résultats comparables aux géants propriétaires, tout en garantissant la maîtrise totale des données sensibles. Cette fenêtre d’opportunité historique permet de construire une autonomie technologique durable. Pour les décideurs, l’enjeu n’est plus de savoir s’il faut franchir le pas, mais à quelle vitesse.
Sources: